Table des matières
- Avant-propos
- 1. L'invention de l'ordinateur
- 2. L'ère des pionniers
- 3. La première industrie
- 4. L'ère de la “loi” de Moore
- 5. L'ère du numérique ambiant
Liste des illustrations
- 1.1. Piège à réservoir de force et déclenchement automatique
- 1.2. Métier Jacquard (David Monniaux, Musée des Arts et Métiers, Paris)
- 1.3. Une pascaline signée par Pascal en 1652 (David Monniaux, Musée des arts et métiers, Paris)
- 1.4. Une machine de Turing ajoutant un à un nombre écrit en numération binaire
- 2.1. Configuration de l'ENIAC (US Army)
- 2.2. Schéma général de l'architecture de von Neumann
Liste des tableaux
Table des matières
Ce document vise à présenter rapidement l'histoire de l'informatique, d'Internet et du Web. Il sert de support au cours de même nom délivré en depuis 2009-2010 aux premières années des masters Web éditorial, esDoc, Ingénierie des médias pour l'éducation et Livres et médiation de l'Université de Poitiers.
Yannis Delmas
Ce document a été conçu et mis en forme par Yannis Delmas, © 2009-2014. Ce document a été conçu au format DocBook pour être consulté sous forme de pages Web (HTML) ou sous forme imprimée (PDF). L'auteur remercie les éditeurs du format DocBook, du traitement de texte XML XXE, ainsi que des logiciels associés.
Ce document est libre de droits pour une utilisation pédagogique sans but lucratif. Toute utilisation non pédagogique et/ou en contexte commercial doit faire l'objet d'une autorisation explicite de l'auteur. Tous droits d'adaptation, modification et traduction réservés. Ce document est également libre de droits à fins de diffusion publique gratuite faisant référence à l'auteur, Yannis Delmas, à son site Web, http://delmas-rigoutsos.nom.fr, et conservant le contenu, le titre original et la date de ce document.
Table des matières
Dans ce chapitre nous nous intéresserons à l'invention théorique de l'ordinateur en 1936 et au contexte culturel qui l'aura précédé. Nous verrons que les racines historiques sont très profondes. Il s'agit notamment deux grands mouvements du progrès technique : celui de l'automatique et celui de la mécanique. Nous verrons également, plus loin, que les réflexions sur les communications, en particulier la logique, ont également beaucoup contribué au fond culturel qui conduira à l'invention de l'ordinateur.
La mécanique, dans le sens qui nous intéresse ici, est la conception et la réalisation de mécanismes, de “machines”, capables de suppléer l'Homme ou l'animal. L'automatique vise à concevoir des dispositifs capables d'agir, voire de réagir à leur environnement, de façon autonome, sans intervention extérieure. À l'idéal, ces deux voies convergent donc vers la vie artificielle, vers le robot “androïde”, mythe très ancien puisqu'on le trouve dans l'Iliade sous la forme de servantes d'or mécaniques du dieu Héphaistos[1]. Évoquons aussi la légende de Pygmalion, sculpteur chypriote qui tombe amoureux d'une de ses statue qui prendra vie[2]. On pensera, plus près de nous, à la légende yiddish du golem. Dans tous ces cas, des hommes ou des dieux animent des artéfacts par leur art, leur technique.
« Automate » signifie, en grec, qui se meut de soi-même ou par lui-même. La mise en œuvre la plus ancienne de l'automatique que l'on puisse imaginer (on n'en a pas de preuve directe), en tout cas la plus prototypique, est celle de pièges de chasseurs. Celui-ci remplace un besoin de force physique (la course, la maîtrise d'un animal) et d'adresse (la maîtrise d'une arme), par une habileté technique. Une fois conçu et mis en place il “fonctionne” par lui-même, sans l'intervention de son auteur, voire même en son absence. Le piège peut être un objet très simple et passif, c'est à dire utiliser essentiellement la force de la proie, comme une nasse ou un trou garni de pieux et caché sous des branchages, ou encore un instrument plus complexe, mais toujours passif, comme un collet (où la proie s'enferme), ou enfin une machine active utilisant une réserve d'énergie, par exemple un arbre fléchi comme dans l'exemple ci-dessous.

Le premier automatisme stricto sensu largement utilisé dont nous conservons des traces historiques est la clepsydre améliorée par Ctésibios (300 AÈC-270 AÈC). Une clepsydre, ou horloge à eau, est, pour l'essentiel, un récipient qui marque l'écoulement du temps en se remplissant d'eau peu à peu. Avant Ctésibios les clepsydres se remplissaient généralement à partir d'un réservoir supérieur percé d'un trou très fin. Le problème est qu'un tel écoulement n'est pas régulier (le débit ralentit au fur et à mesure que le réservoir se vide et que la pression baisse). Pour assurer un écoulement constant, une solution consiste à utiliser un réservoir de remplissage dont le niveau est maintenu constant, soit à l'aide d'un trop-plein (peu économe), soit à l'aide d'une soupape d'entrée (c'est la solution de Ctésibios). C'est la première régulation chronométrique attestée. Elle sera suivie par de nombreux autres, comme les régulateurs à boules ou à ressort. Ces mécanismes sont analogiques ; le premier mécanisme de régulation non-analogique connu est la régulation des horloges par un pendule, inventée par Galilée (1564-1642).[3]
Le mot « mécanique », au sens propre, désigne ce qui est relatif aux machines, une machine étant un assemblage d'instrument articulés entre eux. La mécanique, elle aussi, se développe au moins depuis l'Antiquité. Ses avatars les plus emblématiques sont probablement les moulins à eau, en usages dès l'Antiquité, puis à vent, qui diffusent en Europe à partir du 12e siècle, les machines à vapeur, moteur de la révolution industrielle, et les machines à calculer, dont celle que construisit Pascal pour aider son père dans ses calculs comptables fastidieux (cf. ci-après).
La grande aventure des automates mécaniques en Europe commence au 18e siècle. On y invente de très nombreux automates à figure humaine ou animale, simulant telle ou telle action : manger, jouer de la musique, voire parler. Ces automates semblent alors incarner le mythe antique des servantes d'Héphaistos, semblent créer une véritable vie artificielle, au point que certains se laisseront abuser par un remarquable automate Joueur d'échecs… qui n'était en réalité qu'une remarquable marionnette animée par un nain. Ils inspireront au 19e siècle une littérature de fiction qui puisera également dans les légendes plus anciennes de statues animées. Pensons à Frankenstein ou le Prométhée moderne de Mary Shelley (1797-1851) ou à L'Ève future de Villiers de L'Isle-Adam (1838-1889). L'horlogerie automatique, inspirera aussi les philosophes, qui assimileront la marche de l'esprit humain (ou de l'Univers) à un mécanisme d'horlogerie complexe.
À l'époque très répétitifs ces automates étaient de magnifiques œuvres d'art, souvent réalisés par de talentueux horlogers. Pourtant, ils mettaient déjà en œuvre une première forme de programmation à l'aide du dispositif appelé « arbre à cames » inventé dans l'Antiquité : en l'occurrence un cylindre (l'arbre) à picots (les cames), comme dans les boîtes à musique mécaniques actuelles. En tournant le cylindre fait apparaître devant des actionneurs fixes des picots. Les picots poussent des leviers qui induisent des actions mécaniques. Ce dispositif ne resta pas seulement un amusement réservé à une élite : il fut très tôt utilisé dans l'industrie, en particulier pour conduire des métiers à tisser automatiques. Cette programmation sera ensuite transférée sur des cartons perforés. Ces métiers, améliorés par Joseph-Marie Jacquard en 1801, mettaient ainsi en œuvre la première programmation binaire (carton / trou). Le principe du métier Jacquard, qui permet de réaliser des motifs de tissage très complexes et surtout d'industrialiser le dispositif, est toujours en usage aujourd'hui et le carton perforé est longtemps resté le moyen de programmer les gros ordinateurs. Il est également toujours utilisé sur les orgues de Barbarie.

Le métier Jacquard a été inventé avec l'idée de remplacer le travail des enfants dans l'industrie textile. Ce fut une réussite et un échec : réussite parce que les enfants furent effectivement remplacés par des métiers automatiques, échec parce qu'inemployés par le textile, les enfants ouvriers seront réorientés vers d'autres industries, plus dures encore. Industriellement, la situation est, elle aussi, contrastée : les métiers Jacquard connurent une faveur considérable[4], mais cette réussite installa durablement l'idée que la machine automatique avait vocation à priver l'ouvrier de son travail, à remplacer l'Homme. Le métier Jacquard conduira à la révolte des Canuts (les ouvriers textiles) en 1831. D'autres introductions similaires induiront des mouvements anti-machines, parfois très violents. Pourtant la machinisation débutée au 18e siècle et qui se développa au 19e et au début du 20e siècle recourait globalement assez peu à l'automatisation. À cette époque on était, bien entendu, encore très loin de l'existence des ordinateurs.
Peut-être inspiré par cette histoire, paraît en 1920 la pièce de théâtre RUR (Rossum's Universal Robots) du tchèque Karel Čapek (1890-1938), qui met en scène des machines créées par l'Homme, qui finiront par l'anéantir : les robots. C'est la première occurrence de ce mot. La science-fiction, qui n'existait pas encore, puisera là un thème récurrent de son inspiration.
À l'époque de la seconde Guerre mondiale les ordinateurs n'existaient pas encore. En revanche, l'industrie et le commerce connaissaient depuis longtemps les machines à calculer.
Figure 1.3. Une pascaline signée par Pascal en 1652 (David Monniaux, Musée des arts et métiers, Paris)

Le premier témoignage connu d'une machine à calculer est un courrier adressé à Kepler en 1623, mais celle-ci semble être restée inconnue jusqu'au 20e siècle. La première machine réellement diffusée est l'œuvre de Blaise Pascal (le philosophe, 1623-1662). La pascaline, conçue en 1641 et réalisée en 1645, sera produite en grand nombre (pour l'époque). Avec le temps les machines à calculer deviendront de plus en plus sophistiquées, commodes d'utilisation et bon marché. Dès la fin du 19e siècle on sait que la demande est forte, en particulier dans les commerces de détail, pour les activités quotidiennes, et dans le domaine du recensement. Par exemple, la société IBM, qui dominera plus tard le marché informatique, fut crée en 1896 par Herman Hollerith sous le nom « Tabulating Machines Corporation »[5]. Cette forte demande suscitera des améliorations successives, notamment le clavier, l'imprimante et une gestion de la retenue permettant d'utiliser de grands nombres sans bloquer la mécanique. Ces évolutions permirent notamment de construire des calculateurs proprement colossaux, en particulier aux États-Unis et en Allemagne. Comme pour le père de Pascal, il ne s'agissait pas tant d'effectuer des calculs particulièrement complexes mais simplement de faire plus rapidement des calculs répétitifs et très nombreux. Après les calculateurs purement mécaniques animés par une manivelle, puis un moteur thermique pour les plus gros, arrivèrent les calculateurs électromécaniques (le Harvard MARK 1, le Model 1 et les premiers Z allemands) et électroniques (ABC, ENIAC), à base de relais “téléphoniques” et de tubes à vide (puis de transistors). En 1941, le Z3 de Konrad Zuse est le premier calculateur universel programmable. En 1946, l'IBM 603 est le premier calculateur électronique commercialisé.
Pourtant, malgré toutes ces évolutions, jusqu'à la fin de la seconde Guerre mondiale, le principe général d'organisation de ces calculateurs reste fondamentalement le même : celui de la pascaline et du boulier (mais avec une infrastructure plus performante et parfois plus ou moins programmable)… Précisément, ces machines sont des assemblages de compteurs incrémentés par les opérations successives.
Deux exceptions, toutefois. En 1821, l'anglais Charles Babbage (1791-1871) conçoit les plans d'un calculateur universel programmable en s'inspirant des travaux de Jacquard. Babbage ne réalisera qu'une petite partie de sa machine, trop complexe pour l'époque et bien trop coûteuse. En terme de programmes, on considère souvent qu'il avait eu l'idée d'un mécanisme de commande incluant le conditionnel, mais en réalité rien n'est sûr : on interprète là un écrit court et obscur d'Ada Lovelace. Son influence effective sur le développement du calcul et de la jeune informatique n'est, en tout cas, guère décelable. La seconde exception est Konrad Zuse qui développa pendant les années 1930 un calculateur universel à programme enregistré, mais sans encore de conditionnel. Zuse, très fécond, sera longtemps le moteur (isolé) de la recherche allemande dans le domaine.
C'est à l'occasion de la seconde Guerre mondiale que ces machines sortiront des simples applications calculatoires et rejoindront l'histoire de l'informatique.
Les calculateurs auraient certainement pu progresser encore longtemps sans devenir des ordinateurs. Entre les deux, il n'est pas qu'une simple différence de degré. Nous verrons que l'ordinateur introduit plusieurs différences majeures par rapport aux calculateurs. Pour le comprendre, nous devons revenir en arrière dans le temps. L'histoire de l'ordinateur proprement dit commence bien avant ses mises en œuvre matérielles, avec des recherches fondamentales de logique et d'algorithmique qui mettent en jeu des objets mathématiques très abstraits. Leur réalisation attendra la “faveur” de la seconde Guerre mondiale et de la guerre froide qui s'ensuivra. Plus encore, l'informatique s'appuie sur de nombreuses évolutions (voire révolutions) conceptuelles très antérieures, de l'ordre du siècle parfois. Toutes sont liées à la communication en général ou aux télécommunications en particulier.
L'élément le plus central de toute théorie de l'information, le changement conceptuel le plus fondamental, est la séparation fond-forme, l'articulation arbitraire qui peut s'établir entre un signifié et un signifiant, pour formuler cela en termes modernes (Ferdinand de Saussure, 1857-1913). Cette séparation, fondamentalement en germe dans le principe de l'écriture alphabétique, avait déjà intéressé les théoriciens du langage antiques et médiévaux, avant la linguistique moderne. Elle existait également dans un autre champ très pratique, là aussi depuis l'Antiquité, celui du cryptage de la correspondance pour des raisons de confidentialité, quel que soit son transport : à pied, à cheval ou électrique. Une des méthodes, simple, consistait à remplacer des lettres, des mots ou des expressions par des écritures spécifiques connues des seuls émetteurs et destinataires.
Issue de ces réflexions sur le langage et de la nouvelle algèbre, qui se met en place au 19e siècle, la logique moderne reprend systématiquement et à nouveaux frais la question de l'articulation entre le sens, en particulier les valeurs de vérité (vrai/faux), et les notations, particulièrement dans le domaine mathématique. Dans un premier temps, suivant des principes remontant à l'arithmétique binaire de Leibniz (17e s.: 1646-1716) et au diagrammes d'Euler (18e s.: 1707-1783), les travaux de George Boole (19e s.: 1815-1864) définissent une algèbre, un calcul, des valeurs de vérité. Ces travaux eurent un impact considérable sur la logique naissante du début du 20e siècle. On montra, dès la fin du 19e siècle, que cette logique pouvait être mise en œuvre par des relais “téléphoniques”[6].
Parmi toutes les questions théoriques qui intéressaient la logique à cette époque, une en particulier fut déterminante pour l'informatique. Beaucoup de mathématiciens pensaient à l'époque que le travail de démonstration mathématique était “mécanique” et qu'il était en principe possible de concevoir un procédé systématique permettant (potentiellement au bout d'un temps très long) de résoudre toute question bien formulée. Cette idée conduisit dans un premier temps à axiomatiser les mathématiques, puis, dans un second temps à formaliser la notion-même de procédé de calcul.
Aujourd'hui on appelle « algorithme » un procédé de calcul décrit de façon systématique. Il permet, certaines données étant fournies, de produire un certain résultat (généralement la solution d'un problème donné). On connaît depuis l'Antiquité (au moins) de tels procédés, par exemple l'algorithme d'Euclide qui permet de poser une division de nombres entiers. Le nom « algorithme » a été donné en l'honneur du mathématicien perse Al-Khwârizmî (~780-~850) qui est à l'origine de la notation symbolique et de l'introduction du zéro indien dans l'aire culturelle arabe et qui rédigea une encyclopédie des procédés de calcul connus à son époque. Dans le domaine de l'automatique, le mot sera conceptuellement renforcé au 19e siècle par Ada Lovelace (1815-1852). Les logiciens du début du 20e siècle, en particulier Kurt Gödel (1906-1978), Alan Turing (1912-1954) et Alonzo Church (1903-1995), firent de ces algorithmes des objets mathématiques, à propos desquels il devenait donc possible de démontrer des théorèmes.
Jusqu'aux années 1930, les mathématiciens pensaient généralement qu'il existait des algorithmes pour résoudre chaque problème et même un algorithme universel susceptible de trancher tout problème. Émise par Leibniz, cette hypothèse sera formulée en termes rigoureux par le mathématicien David Hilbert (1862-1943) : existe-t-il un procédé mécanique permettant de trancher tout problème mathématique formulé de manière précise ? Hilbert était un immense mathématicien, très influent, et ce programme suscita de nombreuses recherches, dont émergea la logique mathématique. Les travaux de Gödel, Turing et Church montrèrent par trois approches différentes qu'un tel procédé ne peut pas exister.
L'objet mathématique inventé à cette fin par Turing, qu'il décrit en 1936, donc bien avant les premiers ordinateurs, est sa fameuse « machine de Turing »[7]. Ses principaux éléments sont : une bande infinie constituée de cases mémoire, un module de lecture/écriture de la bande et une unité de contrôle automatique permettant à chaque étape d'écrite une donnée puis de se déplacer à gauche ou à droite, le tout en fonction de son état antérieur. Il s'agit bien d'un dispositif universel : il permet de mettre en œuvre n'importe quel algorithme. Précisément (c'est ce qu'on appelle la « thèse de Church ») : tout traitement d'information réalisable mécaniquement peut être mis en œuvre par une machine de Turing appropriée. Si la machine de Turing avait eu une contrepartie matérielle, ç'aurait été la première machine à programme enregistré capable de traiter de façon universelle de l'information, autrement dit le premier ordinateur. La thèse de Church peut s'interpréter, aujourd'hui, en disant que tout traitement systématique d'information peut être réalisé par un ordinateur correctement programmé et suffisamment puissant. Attention : ceci ne signifie pas que tout problème est résoluble mécaniquement, seulement que ce qui est résoluble mécaniquement l'est informatiquement.
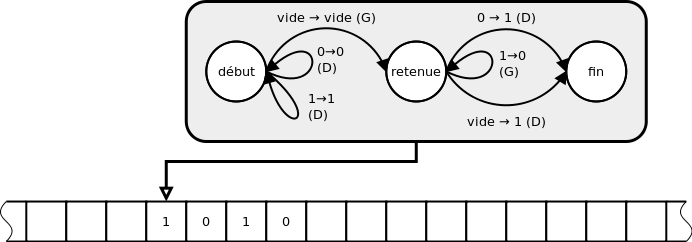
Dans son article de 1936, On Computable Numbers with an Application to the Entscheidungsproblem, Turing fonde ainsi l'informatique, à la fois la science informatique et ce qui sera plus tard la technique informatique. Il donne aussi la première définition systématique des programmes informatiques.
Conceptuellement, ce précurseur théorique des ordinateurs est fondamentalement immatériel puisque les machines de Turing ne sont rien moins que des objets mathématiques. Un autre fait aura une incidence historique considérable : la notion-même de machine universelle porte en elle le fait que programmes et données, tous les programmes et toutes les données, sont fondamentalement de même nature.
[1] L'Iliade mentionne d'ailleurs d'autres « automatoi » : des trépieds, des charmeuses, des chiens de garde et autres animaux, un géant de bronze. Héphaistos est crédité de nombreuses autres créations admirables qui ne surprendraient dans aucune œuvre de science-fiction moderne.
[2] La forme la plus classique de la légende de Pygmalion et Galatée se trouve dans les Métamorphoses d'Ovide.
[3] Pour en savoir plus sur les automates, cf. [Verroust, s. 3 « l'histoire... »]. Attention, cette référence ne distingue pas comme nous entre mécanisme et automatisme (distinction il est vrai parfois un peu artificielle, les deux étant souvent intimement liés).
[4] En 1812 il y avait en France 11 000 métiers Jacquard [Breton, p. 46].
[5] Elle deviendra IBM en 1924, bien avant l'invention des ordinateurs. En 1890, ces machines à tabuler réussissent la prouesse de permettre à l'administration étatsunienne d'effectuer un recensement général de la population en trois ans seulement.
[6] En 1886, en 1910 et à nouveau en 1937. Cf. [Verroust, s. 5 « L'évolution... »] pour plus de détails sur ce point.
[7] Cf. le cours de Technologies informatiques et multimédias.
Table des matières
Nous appelons « ère des pionniers » les temps des tout premiers ordinateurs, qui seront d'abord construits à l'occasion de la seconde Guerre mondiale et de la Guerre froide qui s'ensuit. Cette période couvre, grossièrement, la seconde moitié des années 1940 et les années 1950.
L'histoire de l'informatique théorique (la logique) et celle des technologies de calcul qui lui donneront corps se rejoignent à l'occasion de la seconde Guerre mondiale, au Royaume Uni et aux États-Unis d'Amérique.
Contrairement à la première Guerre mondiale, guerre de positions et de confrontations étendues et durables, la Seconde guerre mondiale est marquée par les techniques de communication et de transport. C'est éminemment une guerre d'actions et de mouvements. Ceci sera déterminant dans l'avènement de l'informatique.
Qui dit actions et mouvements dit ordres d'actions et de mouvement… donc cryptage des communications. Le premier volet de l'aventure commence peu avant la guerre proprement dite, en 1931 : l'Europe sentait déjà poindre la menace de l'Allemagne nazi. Celle-ci utilisait alors un système mécanisé de cryptage, appelé enigma, dont le chiffre (le code) changeait chaque jour. Une équipe polonaise de cryptanalyse, grâce à l'espionnage et aux mathématiques, réussit à en comprendre le fonctionnement et finalement à produire en 1934 des machines, appelées « bombes », testant systématiquement de nombreuses combinaisons enigma. Il s'agissait de sorte de calculateurs spécialisés, entièrement mécaniques. Le dispositif passa en Angleterre après la chute de la Pologne et donna lieu à la création d'un centre de cryptanalyse à Bletchley Park qui fit appel, notamment, à l'un des meilleurs mathématiciens de l'époque : Turing — le même Turing que celui de la « machine de Turing ». Turing inventa une méthode très élaborée qui permettait de casser les chiffres enigma successifs (la méthode était régulièrement améliorée) en moins d'une journée (durée de validité d'un chiffre). Plus tard, il fut également à l'origine d'une machine plus performante encore que les “bombes” cryptanalytiques, le second calculateur programmable moderne, opérationnel en décembre 1943, qui devait pouvoir attaquer le dispositif de cryptage du haut-commandement lui-même : Colossus. [Singh, chap. 4]
Mouvement toujours, le second trait caractéristique de la seconde Guerre mondiale, était de faire intervenir abondamment (c'est peu dire) des projectiles. Qui dit projectiles, dit balistique… si on veut un tant soit peu atteindre sa cible. Or chaque canon, pour chaque type de projectile et éventuellement chaque condition de tir (de vent, par exemple) nécessite une table balistique permettant de régler l'angle du canon en fonction de la distance de la cible. Dès avant la guerre, toutes les armées lourdement artillées avaient donc d'immenses besoins en calculs relativement simples mais très répétitifs. Les calculateurs humains, mêmes munis de machines à calculer restaient lents et surtout, faisaient de nombreuses erreurs dans ces calculs fastidieux. Pour cette raison, l'armée étatsunienne investit abondamment dans les calculateurs électromécaniques, puis électroniques. En 1946, l'ENIAC fut le premier calculateur à calculer une trajectoire plus rapidement qu'un projectile. Il entrait en service trop tard pour contribuer à la guerre mais participa à la conception des armes nucléaires [Breton, pp. 108-109]. À la même époque Zuse, en Allemagne, construisait des calculateurs embarqués pour bombes volantes, permettant une première forme de guidage [Breton, pp. 63 sqq.]. Dans ces deux cas les coûts de recherche et développement étaient considérables — à la mesure d'une commande militaire en temps de guerre.
Ces deux légendes établirent le nouveau « cerveau électronique », comme « dieu des victoires », selon la formule de [Truong]. Le calculateur, et plus tard l'ordinateur, devenaient le symbole même de la performance, de l'avantage technique décisif (c'est à dire qui décide de la victoire). Pendant les deux crises suivantes, la guerre froide puis la crise (donc la guerre) économique permanente d'après les chocs pétroliers, l'ordinateur s'imposait dans les discours comme l'arme absolue, l'outil qui devait permettre de triompher de tout. En parallèle, la science-fiction s'imposait comme genre littéraire et dépeignait volontiers l'ordinateur ou les robots comme le nouvel esclave[8]. De fait la machine devenait concurrente de l'Homme comme force de production : l'outil n'était plus nécessairement le prolongement de la main.[9]
Deux exemples. [Breton, p. 68] décrit ainsi le Harvard MARK 1 : « L'aspect extérieur de la machine était impressionnant : elle mesurait 16,6 m de long, 2,6 m de hauteur et comprenait 800 000 éléments. La machine pesait 5 tonnes et il fallait plusieurs tonnes de glace chaque jour pour la refroidir. ». Bien entendu cette machine n'était pas destinée qu'à calculer : c'était un monstre, c'est à dire un objet destiné à être montré, un signe extérieur de puissance. En 1949, alors que la Guerre froide était déjà bien installée, l'URSS se dotait de l'arme nucléaire. Comme les Soviétiques disposaient de bombardiers à long rayon d'action les Étatsuniens devaient se doter d'un système de surveillance et d'interception capable de répondre promptement. Or les systèmes radar de l'époque, fondés sur la vigilance humaine, n'étaient pas suffisamment réactifs. Les États-unis mirent donc en place un réseau de radars automatisés, SAGE, capable de guider une interception en temps-réel. La guerre devenait une guerre de vitesse où l'Homme ne pouvait plus suivre. L'ordinateur dépassait explicitement les capacités de l'Homme dans un domaine considéré comme intellectuel. Certains se prirent à imaginer un monde où un « pur cerveau », un grand ordinateur, pourrait superviser l'humanité entière pour assurer son bien-être.
Aujourd'hui cette idée évoque le célèbre roman de G. Orwell, 1984, paru à la même époque (1949). Pourtant, celui-ci vise les totalitarismes, qui ont prospéré à l'époque. Les penseurs qui attendaient alors le salut d'un pur cerveau électronique, avaient peut-être en tête les totalitarismes, les meurtres de masse et l'apocalypse guerrière, toutes œuvres humaines, qui s'étaient récemment déroulées sous leurs yeux.
L'idée du « dieu des victoires », de fait, ne rencontra, pour ainsi dire, aucune résistance — ni de véritable alternative. Même les étudiants rebelles des années 1960 ne s'y sont pas opposés. Ils s'opposèrent seulement à l'informatique de leur époque, pas au « dieu des victoires », en créant la micro-informatique et le mouvement contributif/opensource. Parmi les rares voix discordantes, Truong [2001] compare cette vision de l'ordinateur et du progrès technique à une sorte de dieu auquel nous sacrifiions aveuglément nos enfants. Il souligne combien certains secteurs de l'économie mondiale qui se sont informatisés à tour de bras à la fin du 20e siècle ont perdu en productivité. Il rappelle aussi combien les entreprises et administrations ont été capables de dépenser en peu de temps pour “sauver” l'informatique de l'hypothétique « bug de l'an 2000 » alors que les problèmes de faim et de développement du Monde n'auraient mobilisé qu'une partie de cet argent. Ceci montre l'échelle des valeurs du début du 21e siècle.
Historiquement, la commande d'État, en particulier la commande militaire étatsunienne, a été déterminante dans la création de l'industrie informatique. Dans certains cas, comme le système radar SAGE, les connaissances acquises pour le compte de l'armée pouvaient être transférées au domaine civil. Dans de nombreux autres, les produits civils étaient directement dérivés de produits militaires, ce qui fournissait un investissement en recherche et développement gratuit à toutes les sociétés qui travaillaient pour les USA. « La seule grande invention de l'informatique qui n'ait pas vu le jour dans un laboratoire sous contrat militaire (pendant la première informatique), le transistor, sera rapidement cédée par les laboratoires Bell à l'ensemble de l'industrie, dans le but explicite de ne pas freiner la diffusion de cette nouvelle technologie dans les applications militaires » [Breton, p. 180]. Durant la première génération informatique (années 1950) et le début de la seconde (années 1960) la commande d'État étatsunienne absorbe une part considérable de la production[10]. Ceci sera déterminant dans la prépondérance des États-unis : 90% de parts de marché à cette époque [Breton, p. 182].
Même si tous les éléments du puzzle sont présents en 1945, il n'est pas encore possible, à cette date, de parler d'ordinateur. En effet, tous les calculateurs de l'époque sont fondamentalement conçus sur le même modèle que les premières machines à calculer, des bouliers très améliorés. Même l'ENIAC (1946), longtemps qualifié à tort de premier ordinateur[11], avec son électronique révolutionnaire capable de battre à 200 000 pulsations par seconde, nécessitait une saisie préalable et des données et des étapes de calcul à effectuer. À cette époque on ne programmait pas encore : on configurait la machine en vue de tel ou tel calcul (p.ex. sur la photo suivante). L'électronique est bien un ingrédient de l'informatique moderne, le plus visible, mais certainement pas le plus déterminant. Pourtant de nombreux acteurs et observateurs parlent de « cerveaux géants »[12] pour désigner ces immenses calculateurs (moins puissants toutefois que les puces contrôlant aujourd'hui notre électroménager).

La période qui va de la fin des années 1930 aux années 1950, était un temps de bouillonnement intellectuel pour comprendre le comportement, la communication et l'information. C'est à cette époque que se développent ou se répandent le béhaviorisme, la cybernétique et le structuralisme.
La convergence des deux ingrédients de l'ordinateur (conceptuel et technologique) se fait, semble-t-il, par le plus grand des hasards, quand en août 1944, pendant la guerre, un responsable de la supervision militaire de l'ENIAC croise sur un quai de gare John von Neumann (1903-1957), probablement l'un des plus grands logiciens du 20e siècle (et aussi l'un des plus grands mathématiciens, l'un des plus grands économistes et un très grand physicien) [Breton, pp. 75-77]. Il lui demande son avis sur l'ENIAC (qui n'était pas encore opérationnel) et des propositions pour construire son successeur. À la suite de nombreux échanges, von Neumann publiera un pré-rapport qui définit l'architecture, dite « architecture de von Neumann », du successeur de l'ENIAC, l'EDVAC, et, de fait, de (quasi) tous les ordinateurs qui suivront, jusqu'au début du 21e siècle : First Draft of a Report on the EDVAC (1945).
La conception en est résolument nouvelle : le calculateur devient une machine arithmétique, logique et, plus généralement, de traitement de l'information, il est doté d'une vaste mémoire permettant de stocker et des données et des programmes enregistrés, qui ne sont désormais plus fondamentalement différents des autres données (idée issue des travaux sur les machines de Turing), et, surtout, il est piloté par une unité de commande interne (idée de von Neumann) [Breton, pp. 80-82]. L'ordinateur devient donc entièrement automatique, première révolution.
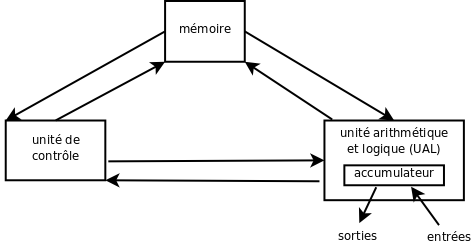
Deuxième révolution, qui justifiera une terminologie nouvelle : il ne s'agit plus désormais de calculer, mais de traiter de l'information binaire. Précisément, les ordinateurs seront des machines universelles, au sens mathématique du terme, c'est à dire capables d'implémenter tout algorithme, en principe (c'est à dire à condition de disposer de ressources suffisantes). Le mot « informatique » sera créé en 1962 par Philippe Dreyfus pour désigner la nouvelle discipline, scientifique et technique : c'est, littéralement, l'automatique (-matique) de l'information (infor-). C'est l'occasion de préciser un peu ce dernier mot, « information ». Il signifia d'abord façonnage (mise en forme) puis instruction (instruire une personne ou instruire une affaire judiciaire) pour désigner finalement un simple fait rapporté (par un journaliste, par exemple). Le sens technique apparaît en 1927 (Ralph Hartley, 1888-1970) [Breton, p. 37]. Il sera précisé peu à peu et aboutira en 1948 à la Théorie mathématique de l'information de Claude Shannon (1916-2001), qui l'établira sur une base mathématique solide. Aujourd'hui ce sens précis et le sens courant continuent à coexister, ce qui ne clarifie pas toujours les débats… Quand on oppose l'information à la connaissance ou à la donnée, de quel sens s'agit-il ?
En 1955, pour commercialiser son premier ordinateur de grande diffusion (les précédents étaient destinés à l'armée ou à la recherche), la société IBM France fait appel au philologue Jacques Perret (1906-1992) pour suggérer un nouveau mot, le mot « calculateur » ne répondant plus à la diversité des tâches désormais possibles. Celui-ci propose de renouveler le terme « ordinateur », qui à l'origine désignait Dieu mettant de l'ordre dans l'Univers — pouvait-on alors viser plus bas que Dieu ? En anglais, le passage de calculator à computer est beaucoup moins impliquant. Avec le mot « ordinateur » la machine passe au second plan derrière l'information et son traitement : l'ordinateur c'est le pouvoir qui vient avec le savoir. Souvenons-nous de la maxime d'Auguste Comte : « Savoir pour prévoir, afin de pouvoir », souvent résumée en : « savoir, c'est pouvoir ». Rappelons-nous que Turing comme von Neumann visaient un véritable cerveau artificiel, modèle réduit du cerveau humain. Cette image, malgré la banalisation des ordinateurs, est encore vivante aujourd'hui.
La première partie de l'histoire de l'objet industriel « ordinateur » est traditionnellement découpée en périodes, appelées « générations », qui recoupent à la fois une base technologique, une approche des usages et une forme de diffusion commerciale. En caricaturant à l'extrême, la gestation de l'ordinateur va de 1936 (l'article de Turing) à 1945 (le rapport de von Neumann) ou 1948-49 pour les premiers ordinateurs à proprement parler. La première génération correspond aux premières mises en œuvre de l'architecture de von Neumann à base de tubes à vide, jusqu'à la fin des années 1950. On parle généralement de deuxième génération pour désigner les ordinateurs utilisant des transistors (à partir de 1959) et de troisième génération pour ceux utilisant des circuits intégrés (1966). Elles correspondent à de très “gros” ordinateurs, chers et de diffusion limitée. Nous verrons plus loin que les choses changeront en 1971 avec l'emploi de micro-processeurs, qui permettront l'émergence des micro-ordinateurs et l'extension des publics et des usages. Revenons, pour l'instant, à la première génération d'ordinateurs, qui utilise des tubes à vide pour mettre en œuvre les circuits dits « logiques », les circuits qui stockent et manipulent l'information.
Au cours de l'histoire des TIC trois fées se passent le relais… souvent deux s'opposent à une troisième : la fée militaire, la fée scientifique et la fée marchande. Avec von Neumann, les deux premières gagnent contre la troisième et assurent aux ordinateurs un bel avenir. La logique commerciale aurait voulu que l'invention des ordinateurs relève d'un brevet. Ceux-ci seraient alors probablement longtemps restés la propriété de quelques uns et n'auraient pas connu le foisonnement considérable qu'on a pu observer (certes largement dominé par IBM). À l'époque John Eckert et John Mauchly, les pères de l'ENIAC et porteurs de son successeur, l'EDVAC, tentèrent effectivement d'imposer un brevet. Von Neuman, qui était un universitaire, adhérait lui à l'éthique scientifique de la libre circulation des idées. Il publia en urgence le fameux rapport sur la nouvelle architecture au titre d'un contrat militaire, donc gouvernemental, ce qui, aux États-Unis d'Amérique, impose une publication dans le domaine public (pour tout ce qui n'est pas secret, bien sûr). Il donna également de nombreuses conférences sur le sujet, plantant ainsi généreusement la graine de l'ordinateur.
Cette concurrence entre la logique marchande des brevets et la logique publique de non-patrimonialité des idées[13] ne sera tranchée par la justice (en faveur du domaine public) qu'en 1947. Entre temps l'EDVAC, qui fut le premier ordinateur conçu, prit un retard considérable — il ne sera opérationnel qu'en 1951 [Breton, pp. 87-89]. De fait, l'honneur d'être le premier ordinateur opérationnel lui fut ravi par le Manchester MARK 1, projet soutenu, en Grande Bretagne, par la Royal Society. Le premier programme enregistré fut exécuté sur cet ordinateur le 21 juin 1948 [Breton, pp. 92-93]. Retenons toutefois que cet honneur n'est que commémoratif ; en termes d'histoire des technique cela n'a pas grand sens de couvrir de lauriers ce projet particulier : les tout premiers ordinateurs ont été développés en même temps sur une durée suffisamment longue pour qu'aucun ne puisse réellement prétendre être à l'origine des autres. On trouve d'ailleurs des palmarès différents selon les auteurs, en fonction de ce que chacun considère comme déterminant. Les tout premiers ordinateurs sont, par ordre alphabétique : le BINAC (suivi par l'UNIVAC, Eckert et Mauchly), l'EDSAC (Cambridge), l'EDVAC, la machine IAS (Princeton, von Neumann) et le Manchester MARK 1 [Breton, pp. 87 sqq.]. Le seul acte de naissance incontestable, que nous retiendrons, est le rapport de von Neumann.
La fée scientifique, en particulier von Neumann, assura une large diffusion à la nouvelle conception[14]. La fée militaire, elle, assurait le financement d'une très grande part de l'investissement en recherche et développement nécessaire pour concevoir les nouvelles machines. IBM, notamment, s'engage dans l'aventure des ordinateurs via un contrat pour l'armée étatsunienne (pour produire l'IBM 701). Rappelons qu'IBM était au départ un fabriquant de machines de bureau (comme son homologue français Bull).
[Singh] Histoire des codes secrets. J.-C. Lattès. 1999. Pour des détails sur le Colossus, on pourra consulter l'article spécialisé de Brian Randell.
[Verroust] Histoire, épistémologie de l'informatique et Révolution technologique. Université de Paris VIII. 2006 (c. 10/4/2008). en ligne : http://hypermedia.univ-paris8.fr/Verroust/cours/TABLEFR.HTM.
[8] Deux repères culturels : 1941, Isaac Asimov invente les « trois lois de la robotique »… et le mot « robotique » lui-même. 1956, Robby, le robot à tout faire du film Planète interdite.
[9] Cette concurrence de la machine date bien sûr d'avant le 20e siècle. Sans attendre l'automatisation, elle est déjà présente dans la mécanisation qui porte la révolution industrielle, nous l'avons vu plus haut.
[10] En juillet 1964 les marchés d'État correspondent à plus du quart du parc informatique étatsunien. Fin 1966, ils représentent près du tiers de ce parc. Source : OCDE, cf. [Breton, p. 181].
[11] C'est toujours le cas sur Wikipedia (VF, c. 6 avril 2009).
[12] Santiago Ramón y Cajal (1852-1934) formule la théorie neuronale dès la fin du 19e siècle.
[13] En réalité, si les idées développées sur fonds publics sont en pratique hors du champ patrimonial, la théorie est différente : les Étatsuniens considèrent que ce qui a déjà été payé une fois par le contribuable au travers d'un contrat avec l'État n'a pas à être payé une seconde fois au titre de la rémunération d'un brevet.
[14] Von Neumann sera aussi, très directement, le père de l'ordinateur IAS de Princeton.
Table des matières
Cette période est celle de l'industrialisation progressive de l'ordinateur, qui passe de quelques unités existant dans le monde à des centaines de milliers, principalement à destination de la recherche et de grandes entreprises. Cette période va, grossièrement les années 1950 au milieu des années 1970.
Les premières machines, gros calculateurs et premiers ordinateurs, étaient extrêmement coûteux à acquérir, encombrants et dispendieux à faire fonctionner. Mais surtout, ils allaient bien au-delà des besoins civils de l'époque. Beaucoup, y compris certains pionniers, ne voyaient aucun avenir commercial à l'ordinateur : c'était d'abord une technologie de pointe destinée aux laboratoires de recherche et à l'armée. C'est la machine elle-même qui créera le besoin… avec l'aide du transistor à semi-conducteur. En effet, les tubes à vide demandent, pour beaucoup, d'être chauffés, ce qui occasionne une dépense énergétique importante ; ils sont coûteux à fabriquer, d'où un coût d'investissement élevé, et enfin sont fragiles, ce qui oblige à les changer régulièrement, d'où un coût de maintenance lui aussi élevé. Cette fragilité occasionne également des interruptions d'exploitation et limite, de fait, la taille des machines. Tout cela change avec l'invention du transistor.
Les semi-conducteurs sont découverts et le transistor conçu en 1947 (prix Nobel de physique en 1956) au sein des laboratoires Bell. Il sera diffusé très largement dès 1948. Comparés aux tubes électroniques les dispositifs à semi-conducteurs (principalement les diodes et transistors) sont simples, bon marché, peu encombrants, résistants/durables et consomment peu. Autre avantage : les semi-conducteurs peuvent remplacer assez aisément (une fois la technologie maîtrisée) la plupart des anciens dispositifs à tubes. Les coûts d'exploitation et d'acquisition chutent considérablement.
Dans ce secteur tertiaire, l'industrie des machines de bureau, IBM en tête, est déjà très présente. Précisément, cette industrie dispose déjà de circuits de promotion et de distribution. De plus, elle bénéficie d'une solide assise financière qui lui permet de vendre à perte jusqu'à asphyxier de nouveaux entrants, y compris plus performant financièrement et/ou techniquement [Breton]. La clientèle est alors plus importante que l'avantage technologique. À l'époque de la fin des tubes à vide, une industrie informatique s'est donc déjà établie, en dehors des laboratoires universitaires et militaires, d'emblée sous la large domination d'IBM [Randell, pp. 469-471]. Durant la seconde génération (jusqu'en 1966), IBM a pu assurer entre la moitié et les deux-tiers de la production mondiale d'ordinateurs[15].
Le premier ordinateur produit en masse est l'IBM 650. C'est celui pour lequel on invente le mot ordinateur en France. Il est diffusé dès 1954 aux États-Unis d'Amérique et en 1955 en France. Il sera vendu à plus de 1 500 unités dans le monde.
Deuxième grand avantage des transistors : la miniaturisation, première forme de libération technique. Cette course à la miniaturisation sera d'emblée et depuis lors un des principes cardinaux de l'industrie informatique. Principe cardinal vite compris, et très explicitement, par les responsables de DEC (un des principaux fabricants de l'époque), qui lance le nom «mini-ordinateur», inspiré de la minijupe lancée en 1962, pour le PDP-8, qui sera un best-seller de sa catégorie. En 1965, une publicité du PDP-8 montre celui-ci posé à l'arrière d'une décapotable[16]. Tout un programme…
L'opposition est marquée avec les gros systèmes centralisés d'entreprise. Il s'agit désormais de s'adresser à de plus petites organisations, services et même individus. Ce sera un franc succès (près de 50 000 PDP-8 vendus, plus que tous ses prédécesseurs), y compris auprès d'utilisateurs non techniciens (sachant quand même que le prix du PDP-8 ramené en 2012 serait d'environ 19 à 45k€, selon les versions). La voie est désormais ouverte à l'ordinateur pour conquérir une société déjà extrêmement bureaucratisée donc avide de statistiques, de comptes, de bilans et autres rapports. Qui plus est, le secteur tertiaire, très développé et en position de force, est très bien disposé à l'égard de l'innovation technologique.
En 1958, Jack Kilby (1923-2005) et Robert Noyce (1927-1990) inventent indépendamment le circuit intégré, c'est à dire la possibilité de graver des circuits et de nombreux composants sur une même galette de silicium, une même « puce » (chip) — aujourd'hui plusieurs milliards. En 1959 un brevet est déposé. Cette technologie conduira plus tard aux mémoires intégrées (1970) puis aux microprocesseurs (1971) et enfin aux micro-ordinateurs (1972). Cette évolution technologique du matériel (hardware), très rapide et dans la même ligne directrice que la précédente, n'est pas qu'affaire d'informaticiens et d'industriels ; elle a eu une incidence considérable sur la société, chaque évolution technologique marquant l'extension de l'informatique à de nouveaux secteurs de la population.
L'intégration, en particulier la possibilité d'intégrer l'essentiel de l'ordinateur sur une puce, le micro-processeur, ouvrait la voie à une miniaturisation bien plus considérable et une baisse des importante des coûts de fabrication. Accessoirement pour l'époque, elle ouvrait également la voie à une augmentation rapide de la puissance des ordinateurs, comme nous le verrons plus loin. Le plus important, dans un premier temps, fut la baisse du prix. C'est pour cette raison que fut conçu dès 1973 le Micral, premier micro-ordinateur. Il était d'une puissance comparable à celle du mini-ordinateur PDP-8, mais cinq fois moins cher. Le Micral, conçu en France, était construit autour du microprocesseur 8008 d'Intel.
Tableau 3.1. Nombre d'ordinateurs en service[a]
| 1965 | 1970 | |
|---|---|---|
| États-Unis (moyens et gros) | 3 700 | 14 000 |
| Japon (moyens et gros) | 850 | 2 300 |
| Europe (moyens et gros) | 3 580 | 9 800 |
| États-Unis (petits) | 20 000 | 40 000 |
| Japon (petits) | 450 | 4 700 |
| Europe (petits) | 2 500 | 4 700 |
| total | env. 31 000 | env. 75 500 |
[a] Source : OCDE, Écarts statistiques, Paris, 1969, cité par [Breton], p. 192. | ||
Avec l'industrialisation, le chercheur en cybernétique et l'ingénieur concepteur d'ordinateur laissent la place à l'expert informatique, qui prend une place de plus en plus importante dans les grandes organisation qui mettent en place un traitement systématique de l'information. Peu à peu, les données concernant les individus prennent une importance considérable dans la société. En 1974, les États-Unis d'Amérique adoptent une loi informatique et liberté et la France constitue la CNIL. Cette extension toujours plus grande de l'informatique, permise par la miniaturisation et la baisse des prix, conduit, à cette date à une nouvelle période de l'informatique que nous avons appelée «ère de la loi de Moore». Certains auteurs parlent de quatrième génération pour les ordinateurs à base de microprocesseurs.
[15] Source OCDE, citée par [Breton], p. 183. Précisément, IBM représente 66% de la production mondiale en 1962, 50% en 1967. En 1967, IBM et les sept autres plus grands constructeurs étatsuniens (les « sept nains ») représentent ensemble plus de 91% de la production mondiale.
[16] Il est vrai qu'il ne pèse que 110 kg.
Table des matières
Cette période fait suite, par rapport à la précédente, à une mutation profonde tant de la technique de construction, que de la population des utilisateurs, que des usages et, plus généralement, d'une ambition nouvelle pour l'ordinateur. Durant cette période, l'ordinateur devient un produit de masse qui se répand dans de nombreux foyers. Cette période va, grossièrement, du milieu des années 1970, avec l'inversion de la loi de Grosh (1974) à la fin des années 1990, avec la maturité du Web.
La miniaturisation, amorcée avec l'utilisation du transistor (2e génération), considérablement accrue avec l'utilisation des circuits intégrés (3e génération), gagne encore un ordre de grandeur dans la puissance disponible avec l'utilisation des microprocesseurs (on parle parfois de 4e génération). L'essentiel de l'ordinateur est maintenant regroupé sur une puce unique : le microprocesseur. Ce saut qualitatif considérable va amener une rupture majeure dans les usages et la pénétration de l'ordinateur dans la société.
Le premier saut qualitatif est l'inversion de la loi de Grosh, qui intervient en 1974, et peut marquer le début de ce que nous appellerons l'« ère de la loi de Moore ». Cette inversion est le fait qu'à partir de 1974, le nombre d'opérations par seconde et par dollar (de coût d'ordinateur) est bien moindre avec de petits ordinateurs. Avant 1974, en revanche, la productivité informatique était en faveur des gros ordinateurs. De ce fait, il devient donc économiquement plus intéressant de multiplier les ordinateurs plutôt que de pousser au gigantisme. Les séries de production se multiplieront, avec la miniaturisation, et les ordinateurs deviendront de moins en moins chers, à puissance égale. Bien entendu, cette évolution se fait progressivement et la date de 1974 ne doit pas être entendue au pied de la lettre : les gros systèmes ne disparaissent pas du jour au lendemain, ils sont remplacés, peu à peu par les mini-ordinateurs, puis les micro-ordinateurs. Les gros ordinateurs continuent à être vendus, en nombre restreint, même si leur intérêt relatif a diminué.
Le premier microprocesseur, l'Intel 4004, sort en 1971. La micro-informatique, professionnelle, puis personnelle se développe ensuite à partir du milieu des années 1970. En 1972, François Gernelle (1945-) conçoit le premier micro-ordinateur, le Micral N, autour du microprocesseur 8008 d'Intel. Celui-ci suscite de nombreux émules, principalement à destination des hobbyistes, dont beaucoup en kit, vendu quelques centaines de dollars seulement. Parmi eux l'Apple I (1976), rapidement suivi de l'Apple II, qui s'imposa largement dans le secteur des hobbyistes. À la fin des années 1970, Apple a la plus forte croissance du secteur. IBM lance alors, en 1981, l'« ordinateur personnel », le PC, avec une architecture standardisée garantissant une compatibilité ascendante (les « compatibles PC »). L'ordinateur est désormais largement accessible aux particuliers (non nécessairement hobbyistes). Le nombre de machines explose, y compris après les chocs pétroliers. Avant de vendre des ordinateurs, IBM et les autres grandes compagnies vendent d'abord l'idée que l'information est stratégique. Cette idée, qui s'appuie notamment sur les écrits de Wiener et von Neumann, est alors largement diffusée, tant dans l'establishment que dans la contre-culture ( « savoir, c'est pouvoir » ). Plus généralement, avec l'ordinateur on vend la modernité et un nouveau mode d'organisation de l'entreprise, de l'administration. L'information devient une nouvelle matière première, un nouveau carburant. Faisant le parallèle avec le charbon (la machine à vapeur) du 19e siècle, des idéologues technophiles prophétisent l'avènement d'une seconde révolution industrielle. Là où la génération précédente faisait des bestsellers à quelques milliers d'exemplaires vendus, on passe maintenant au million : de 1982 à 1988, IBM vend plus de 15 millions de PC.
En 1985, l'éducation nationale française lance le plan « informatique pour tous ».
En 1965, Gordon Moore (1929-), un des fondateurs d'Intel prédit un doublement de l'intégration chaque année, c'est à dire, grossièrement, un doublement du nombre de transistors intégrables sur une même puce (sachant qu'il n'y a pas que des transistors sur ces puces). Il révisera son optimisme en 1975 en prévoyant que le nombre de transistors des processeurs doublerait à coût constant tous les deux ans. Cette « loi de Moore » est assez bien vérifiée empiriquement. On l'exprime souvent sous la forme simplifiée d'un doublement de puissance brute des ordinateurs (mémoire, capacité des disques, puissance des processeurs) tous les 18 mois. Cette seconde forme n'a pas de définition technique précise, elle est donc invérifiable à proprement parler, mais donne un ordre de grandeur estimatif commode. Si l'on prend l'hypothèse d'un doublement tous les deux ans, on obtient grossièrement un facteur 10 pour 6 ans, 30 pour 10 ans, 200 pour 15 ans et 1 000 pour vingt ans. Il s'agit d'une progression exponentielle fulgurante, qui, bien sûr, ne peut durer éternellement. Sa fin était assez justement estimée pour le début des années 2000, pour des raisons physiques sur lesquelles nous reviendrons plus loin. Ceci fixe les bornes (1971-2005) d'une deuxième ère de l'informatique, que nous appelons l'« ère de la loi de Moore ».
Quel genre de loi est donc la “loi” de Moore ? Certainement pas une loi judiciaire. Ni une loi physique, puisqu'elle décrit, finalement, une vitesse de mise sur le marché de produits. On pourrait y voir une loi historique puisqu'elle décrit une série de faits historiques (bien avérés d'ailleurs). Souvenons-nous donc qu'elle fut formulée avant ces faits ! La loi de Moore est ainsi d'abord et avant tout un plan de marche, un programme de recherche et développement, pour l'ensemble d'une industrie.
Quelles sont ses conséquences ? Tout d'abord, cette loi s'applique à un nouveau contexte technologique et commercial : le produit dominant de cette période est le micro-ordinateur. Celui-ci est de moins en moins encombrant et de plus en plus accessible financièrement pour les ménages. Il devient une composante de l'électroménager domestique. Comparons l'ordinateur à d'autres biens d'équipement, lave-linge ou télévision. Dans une première phase les ménages les plus aisés s'équipent, les constructeurs s'efforcent donc de valoriser leurs marques : celui qui fait de meilleures machines peut espérer en vendre plus ou plus cher. Dans un second temps, quand les ménages sont largement équipés, il n'est plus possible de vendre autant de machines et il faut donc forcer le renouvellement du parc : soit en abaissant leur durabilité (lave-linge), soit en imposant des ruptures techniques (télévision). Revenons aux ordinateurs. Nombre d'unités centrales conçues aujourd'hui, avec une bonne maintenance, peuvent durer plus de dix ans. Contrairement aux machines à laver, les ordinateurs utilisent assez peu de pièces mobiles, il n'est donc pas aisé de diminuer artificiellement leur durée de vie physique. L'industrie s'appuya donc sur la loi de Moore. Puisque cette loi était connue des éditeurs, ceux-ci pouvaient développer des logiciels gourmands en puissance au moment de leur conception : la puissance des ordinateurs au moment de la diffusion devant (en principe) devenir suffisante[17]. Autrement dit, l'achat de nouveaux logiciels commande l'achat d'un nouveau matériel. Les constructeurs, de leur côté, font leur possible pour se tenir à la loi de Moore afin d'entretenir la boucle vertueuse (et introduisent suffisamment de nouveautés dans le hardware). Ainsi tout nouvel ordinateur appelle l'achat de nouveaux logiciels. La multiplication des périphériques, utilisant des protocoles (logiciel) et des connecteurs (matériel) nouveaux toutes les quelques années, complète la nasse. La clef de voûte est, comme toujours, idéologique : après trois ans un ordinateur n'est pas considéré comme « vieux » ou ayant moins de fonctionnalités, mais comme « obsolète. » Les mots sont importants. Avec le temps, bien entendu, les consommateurs se sont adaptés et s'efforcent toujours d'acheter simultanément l'ordinateur, les périphériques et les logiciels. La pression d'évolution reste toutefois importante grâce aux logiciels professionnels, aux anti-virus et aux logiciels d'entertainment (de jeu, principalement).
Ce plan de marche induit/traduit une logique qui commande la place des principaux acteurs durant cette période.
Le principal acteur de la période précédente, le constructeur d'ordinateurs, s'effacera progressivement pour céder la place, d'un côté aux constructeurs de composants, en particulier les « fondeurs » de processeurs, et de l'autre aux concepteurs de logiciels, en particulier les « éditeurs » d'applications. En schématisant et en nous limitant aux plus grands, « Big blue » IBM abandonne son leadership à Intel et à Microsoft (« big green »). Dans les années 1980, la production électronique passe des États-unis à l'Asie, au Japon en particulier [Breton, pp. 193-204].
Dans le domaine du matériel, du fait de l'augmentation de la puissance des puces, les gros systèmes perdent la plupart de leurs applications : à partir de 1974, il devient moins coûteux d'utiliser de petites machines, éventuellement en grand nombre, plutôt que les super-ordinateurs de la période précédente. C'est l'inversion de la “loi” de Grosh [Breton, pp. 195-197]. Les mini- puis les micro-ordinateurs s'imposent et conquièrent toujours plus de segments de marché. Dans le même temps la recherche informatique se développe et s'installe dans le paysage scientifique.
Du côté des logiciels, pour assurer une certaine forme de rente, les éditeurs doivent courir l'innovation. Il ne s'agit pas seulement de rendre les logiciels plus performants, mais aussi de les rendre plus « conviviaux », d'augmenter le nombre des fonctionnalités (bien au-delà de l'usage de la plupart des utilisateurs), puis, dans les années 1990, de jouer sur des effets de mode, sur le look des logiciels (et pour Apple des matériels). C'est donc une période extrêmement propice à l'innovation logicielle. Les interfaces Homme-machine (IHM), en particulier, feront des progrès considérables durant cette période. La souris telle que nous la connaissons est développée au cours des années 1960[18]. Elle se répand à partir de 1981 grâce au système Xerox Star puis, surtout au Macintosh (1984). C'est également le Xerox Parc qui développera l'affichage graphique avec fenêtres (GUI), repris et développé ensuite par les principaux systèmes d'exploitation.
Durant toute cette période, la grande majorité des ordinateurs produits ont une architecture de type « compatible PC » (et sa descendance, définie principalement par Intel). Il y a, bien entendu, des alternatives, mais elles représentent des volumes de vente extrêmement faible en regard du courant principal. Ce courant bénéficie de quelques améliorations ponctuelles du hardware, mais il y a, au fond, assez peu de changements. Nous reviendrons ultérieurement sur la principale, le multiprocessing, qui se développera au cours des années 1990 et 2000. Il est nécessaire de d'abord évoquer le développement des réseaux. Mais tout d'abord évoquons rapidement l'évolution du logiciel durant cette période.
Dans la mesure où l'immense majorité des ordinateurs vendus durant cette période relèvent de la même architecture, et même assez précisément puisqu'ils respectent souvent les versions successives du « compatible PC » défini par IBM, puis de l'architecture i386 (et successeurs) définie par Intel, toutes respectant une certaine compatibilité ascendante, le hardware, de l'unité centrale en tout cas, n'a que peu de marge d'évolution. La créativité et l'innovation investiront donc un peu le domaine des périphériques et surtout celui du logiciel (software), qui connaîtra une évolution considérable durant l'ère de la loi de Moore, comparable à celle qu'a connu le hardware durant la période précédente. Périphériques et logiciels prennent progressivement le pas sur le matériel à la fois comme moteur de l'évolution technique et comme source principale de valeur ajoutée. Dans les deux cas, il s'agit d'étendre les services rendus par l'ordinateur, au point d'ailleurs parfois de créer de nouvelles machines qui ne sont plus reconnues comme des ordinateurs par leurs utilisateurs.
L'évolution du logiciel était peu significative et surtout peu séparable de l'évolution du matériel lui-même durant les premières générations, celui-ci étant largement assimilé à de la documentation technique, fournie avec le matériel. Elle devient déterminante à partir des années 1970, au point que David Fayon parle même d'« ère du logiciel » pour désigner une période proche de celle que nous appelons « ère de la loi de Moore ». Cette histoire nécessiterait à elle seule un cours au moins aussi détaillé que celui-ci. Nous nous limiterons, ici, à quelques éléments d'appréciation de l'évolution en remontant un peu en amont de l'ère de la loi de Moore.
À l'époque des calculateurs électroniques et des premiers ordinateurs on ne peut pas réellement parler de programmation ; il serait plus exact de parler d'une configuration de la machine, comme pour les machines de Turing. Pour autant l'architecture de von Neumann amorce un processus durable : les programmes peuvent désormais être enregistrés en mémoire puis sur des mémoires de masse. Ils peuvent donc gagner en complexité, progressivement. Les premiers programmes sont des programmations de la machine : ils décrivent séquentiellement les opérations qu'elle doit effectuer. Il s'expriment d'abord en langage machine puis seront ensuite rendus plus lisibles à l'aide de langages de description de programmes en langage machine : les langages « assembleurs »[19]. Dans les années 1950 et au début des années 1960 les ordinateurs étaient si chers qui fallait les faire travailler en permanence. C'est l'origine des dispositifs de partage de temps (time sharing, 1961) et des systèmes multitâches (1958) puis multiutilisateurs : le moment de réflexion d'un utilisateur peut être le temps de calcul d'un autre. Ces méthodes permettront la mise en place des premiers grands systèmes partagés de banque et de réservation aérienne [Negroponte, p. 95].
Avec l'augmentation en complexité des ordinateurs (années 1970-1980) et surtout l'apparition des périphériques, en particulier de stockage, il devient nécessaire de disposer de logiciels de plus en plus spécialisés : firmware, systèmes d'exploitation, applications. Le firmware s'occupe des fonctions matérielles les plus élémentaires et de l'amorçage du système (c'est le BIOS des PC). Le système d'exploitation gère les périphériques (au début guère plus que l'affichage en mode texte, le clavier et les disques) et l'exécution des applications[20]. Les applications sont au service de l'utilisateur. Plus tard (années 1990-2000), les fonctions se spécialiseront encore, le système d'exploitation, en particulier, se décomposant en de nombreuses sous-unités œuvrant de conserve : noyau, pilotes, HAL, gestionnaire de fenêtres et d'affichage, bibliothèques diverses, serveurs de données etc.
[Verroust] évoquant les années 1980 : « À cette époque les systèmes n’avaient ni la capacité ni la nécessité d’utiliser les systèmes d’exploitation pour mini et grands ordinateurs. Les premiers systèmes d’exploitation appelés moniteurs offraient seulement des fonctionnalités très basiques, et étaient chargés le plus souvent depuis de la mémoire morte. CP/M fut l’un des pionniers en matière de système d’exploitation installé sur un disque (et non sur mémoire morte). Ce système d’exploitation influença largement la conception de PC-DOS. Ce dernier, choisi par IBM comme système d’exploitation pour ses premiers PC, fit de Microsoft l’une des compagnies les plus rentables au monde. Les principales alternatives durant les années 1980 sur le marché des systèmes d’exploitation furent Mac OS en 1984, AmigaOS et Atari en 1985 et OS/2 en 1987. » Les années 1990 voient l'extension de la norme Unix et de systèmes de conception proche : linux (1991), WinNT (1993), MacOS 9 (1999) puis MacOS X (2001). La décennie 2000 voit l'explosion des OS “embarqués” (dont les netbooks et autres iPod). De même que les mini-ordinateurs dépassèrent en nombre puis en usage les gros systèmes, puis que les micro-ordinateurs dépassèrent les mini-, aujourd'hui l'informatique embarquée (téléphones, tablettes, nanos, netbooks, électroménager…) dépasse (largement) la micro-informatique.
Si les firmwares restent longtemps, et encore maintenant, programmés en assembleur, les systèmes d'exploitation et les applications réclamaient des méthodes plus élaborées de programmation.
Le premier vrai langage de programmation effectivement utilisé est le FORTRAN (FORmula TRANslation) mis au point de 1953 à 1957 [Breton, p. 166]. Il s'agit d'un langage impératif, c'est à dire d'une succession d'instructions. D'autres langages seront développés pour répondre à des besoins particulier. Le FORTRAN était destiné principalement au calcul scientifique (il est encore marginalement utilisé, malgré la faiblesse de sa syntaxe). Le COBOL (COmmon Business Oriented Language), créé en 1959, est encore utilisé en gestion. L'Intelligence artificielle, un secteur de la recherche informatique, utilisera abondamment le LISP (1958), langage de programmation fonctionnelle[21], dans les années 1970-1980, puis le PROLOG (1972), langage de programmation logique[22], pour la construction de systèmes experts. Pour les bases de données on conçu un langage de description, de manipulation et de contrôle, le SQL (1970).
À côté de ces langages spécialisés, les programmeurs et les théoriciens avaient besoin de langages généralistes. C'est à cette fin que fut créé ALGOL (1958), dont dériva le Pascal (et ses nombreux dérivés : Turbo Pascal, Delphi...). Pour gagner encore en généricité et en commodité est créé en 1963 le langage de haut niveau BASIC, explicitement dédié aux débutants : Beginner's All-purpose Symbolic Instruction Code. Lui aussi eut une riche descendance, dont le Visual Basic, le VBscript et VB.Net de Microsoft.
Enfin, avec la montée en complexité des programmes, il devenait de plus en plus pénible de traiter et de nommer différemment des procédures similaires du seul fait qu'elles s'appliquaient à des objets différents. On inventa donc, à partir de la recherche en Intelligence artificielle, des langages capables de définir des procédures ou des classes d'objets de façon abstraite, c'était la programmation orientée objet[23]. Aujourd'hui les principaux grands langages de programmation généralistes ont évolué et permettent une programmation objet.
Parmi tous ces langages une famille occupe une place à part par l'influence qu'elle aura sur Internet, les logiciels libres, puis le web. Le C est créé au début des année 1970 de conserve avec le système d'exploitation Unix par Dennis Ritchie et Ken Thompson au sein des laboratoires Bell. Unix (1969) était une forme de réaction aux systèmes d'exploitation extrêmement complexes et lourds de l'époque et en particulier Multics. Il était conçu pour fonctionner sur les petits systèmes (mini-ordinateurs) qui commençaient à se répandre à l'époque. Le C visait un objectif nouveau à l'époque de portabilité. Il deviendra C++ (1985) en acquerrant la programmation objet. Du C++ dérivera une version épurée, Java (1995), pour porter encore plus loin la portabilité et permettre une utilisation comme langage interprété. De Java découlera une simplification, Javascript (1995). Enfin PHP est extrêmement proche, dans son esprit et sa syntaxe, de cette famille de langages. Aujourd'hui, pour la programmation web côté serveur, Java domine largement les grosses applications et PHP les petites. Pour la programmation web côté client Javascript est le standard de fait. Dans l'absolu Java occupe la première place des langages, C la seconde et C++ la troisième[24].
Parmi les éléments les plus déterminants de la révolution industrielle (milieu 18e siècle-milieu 20e siècle) figure probablement les principes de division du travail, non seulement au sens social (répartition entre catégories, classes ou castes) ou au sens économique (qui culmine avec le taylorisme), mais également au sens technique avec la normalisation des pièces détachées. Il en va de même en informatique : une part toujours plus grande du travail des différents logiciels consiste en tâches qui ne lui sont pas spécifiques et qui peuvent donc être standardisées et rédigées une fois pour toute. À l'époque de FORTRAN cette idée est encore extrêmement rudimentaire : le langage permet simplement de définir des sous-programmes. Peu à peu cette notion se formalisera et les “bouts” de programmes, que l'on appelle « procédures » ou « fonctions », se regrouperont (à partir de la fin des années 1950) en ensembles appelés « bibliothèques. » Ces bibliothèques sont intimement liées, dans un premier temps, à un langage et à un système d'exploitation. Par exemple les opérations de manipulation de fichiers ou de communications entre processus, sont très génériques et n'ont pas à relever de chaque application en propre : il est beaucoup plus efficace de disposer de procédures standardisées regroupées en bibliothèques standards. Plus généralement, l'utilisation de telles bibliothèques permet de mettre en oeuvre les principes informatiques (théorisés) de modularité (separation of concerns) et d'encapsulation (information hiding)[25]. Ces principes seront considérablement développés et rendus rigoureux par la programmation orientée objet. Aujourd'hui on appelle « framework » un ensemble cohérent de bibliothèques (voire une seule, dans certains discours commerciaux).
Les applications de grande diffusion apparaissent relativement tard dans l'histoire de l'informatique. Le marché étant d'abord occupé par des programmes conçus à façon. Le premier tableur, Visicalc, est commercialisé en 1979. Aujourd'hui encore les applications destinées au grand public semblent peu nombreuses et dans la plupart des registres, un ou deux acteurs s'accaparent l'essentiel des parts de marché. Ces application constituent, toutefois, un marché considérable et exercent, jusqu'aux années 2000, une influence considérable sur le reste de la production.
Jusqu'aux années 1960, les ordinateurs sont, pour l'essentiel, des machines dédiées à un usage particulier et donc sont au services d'usagers spécifiques et formés, qui peuvent donc s'adapter à l'ordinateur. À partir des années 1960, avec l'apparition des mini-ordinateurs, on voit le début du généralisme, qui sera considérablement amplifié dans les années 1980, avec le nouveau marché des ordinateurs personnels (PC). En 1960, Joseph Licklider[26] écrit La symbiose Homme-machine : l'interface Homme-machine (IHM) devient un élément des systèmes et applications. En 1963, Ivan Sutherland crée la première interface graphique (GUI) pour le logiciel de CAO sketchpad. En 1968, Douglas Engelbart invente souris[27] et fenêtres. De 1971 à 1977, le centre de recherche Xerox PARC développera de nombreux dispositifs qui équiperont, peu à peu, l'ensemble de l'informatique grand public, jusqu'aux années 2000 : l'ordinateur personnel, le modèle WIMP (fenêtres (windows), icones, menus et pointeur) et la métaphore du bureau, la souris, le réseau local ethernet, l'imprimante laser et le traitement de texte WYSIWYG what you see is what you get, 1974) qui sera popularisé par Apple à partir de 1983. La plupart des ordinateurs personnels adopteront un environnement de travail qui suivra les mêmes principes : X window (1984), Macintosh (1984), Windows 1.0 (1985). Tout cela permettra l'apparition et l'extension rapide de la bureautique durant les années 1980. Après une maturation rapide de ces logiciels, ont s'intéressera, durant les années 1990, à l'aspect, aussi bien des documents que des applications elles-mêmes. D'une part, on verra apparaître les premiers logiciels de publication et de communication imprimée et à l'écran ; d'autre part, les éditeurs, en particulier Apple, attachera une importance de plus en plus marquée au look et au design des logiciels.
Du fait de l'extension considérable de l'informatique des années 1980 et le renouvellement rapide des logiciels, apparaissent, dans les années 1990, les premiers phénomènes dits de “pourrissement des bits”. La plupart des applications enregistrent leurs données dans des formats qui leur sont spécifiques, formats qui varient également, pour un même logiciel, d'une génération à la suivante. De ce fait les données ne sont parfois plus lisibles ou plus utilisables en pratique après seulement quelques années. Autre difficulté : l'impossibilité de transmettre des données d'un utilisateur à un autre — ce qui devient de plus en plus gênant avec le développement des communications numérisées, des consolidations et des croisements de données. Quelques informaticiens prennent conscience de ces difficultés dès les années 1980, mais la question ne devient vraiment reconnue, en particulier des décideurs, qu'au cours des années 1990. Elles ont conduit à plusieurs types de réponses, principalement : les logiciels libres, les sources ouvertes (open-source) et les exigences d'interopérabilité. Ces difficultés ont été particulièrement mises en lumière à l'occasion des grandes manoeuvres contre le « bug de l'an 2000. » Elles ont conduit un certain nombre d'États et d'entreprises, au cours des années 2000, à mettre en œuvre des plans d'interopérabilité et de conservation de données.
En 1983, Richard Stallman lançait un appel aux hackers pour la création d'un unix libre : le projet GNU. Linux, commencé en 1991, permet de donner à ce projet toute sa maturité. À l'époque, le mot « libre » (« free ») ne renvoie pas tant à la gratuité qu'à l'absence de secret : ce mot vient de la tradition du mouvement des droits civiques des années 1960 et 1970 [Flichy, p. 224-225]. GNU/linux ne connaîtra qu'un succès d'estime sur les ordinateurs proprement dit, mais il se développera en revanche considérablement sur les dispositifs embarqués qui se développent considérablement au cours des années 2000 : “boxes” d'accès à Internet, settop boxes et autres dispositifs mobiles, en particulier ordiphones et tablettes sous la forme du système Android.
Au cours des années 2000, la puissance des ordinateurs devient considérable, il devient possible à de nombreux ordinateurs de traiter le son et la vidéo, et même de synthétiser des images de scènes complexe (« réalité virtuelle ») en temps réel. Les jeux vidéos prennent une importance considérable durant cette période, tant en terme de temps de jeu, d'influence culturelle, que de marché (dépassant, au début des années 2010 l'industrie cinématographique).
Les années 2000 voient également se développer les logiciels et interfaces web. Nous y reviendrons plus loin.
On confond souvent Internet avec le web, employant un mot pour l'autre. Il s'agit, en fait, de deux choses tout à fait différentes. Internet est un réseau de télécommunication informatique, une infrastructure donc. Par lui transitent le courrier électronique, les messageries instantanées, les jeux en ligne et de nombreux services de transfert de fichiers et de publication de documents. Le web n'est “que” l'un de ces services (aujourd'hui c'est le support de la plupart des systèmes d'information en ligne).
Par l'importance qu'il a pris dans notre vie, Internet devait relever du mythe. Selon la légende qui entoure sa naissance, Internet serait étatsunien, militaire et indestructible. Comme dans tout mythe, il y un peu de vrai et beaucoup de faux. Nous verrons cela en détail dans cette section, mais résumons cela en quelques mots.
Internet est-il étatsunien ? D'un point de vue historique, il est vrai que les prémices de ce qui sera Internet apparaissent aux États-unis ; pour autant le travail de pionnier sur les réseaux à commutation de paquets n'est pas l'exclusivité de ce pays. On ne retient souvent qu'ARPAnet comme ancêtre d'Internet ; en réalité de nombreux autres projets indépendants contribuèrent à l'évolution vers Internet. L'histoire est souvent écrite par les vainqueurs… N'oublions pas les autres acteurs. D'un point de vue technique, Internet est une coalition de nombreux réseaux indépendants relevant de grands opérateurs. Il n'appartient donc à aucun pays en particulier. Pour autant, un certain nombre d'organismes responsables de sa mise en oeuvre ont leur siège aux États-unis ou dépendent plus ou moins directement d'institutions de ce pays.
Internet est-il d'origine militaire ? L'ordinateur était sans conteste un fruit de la Second Guerre mondiale. Sans les occasions données par la guerre (et directement par l'armée) à des Hommes remarquables, l'ordinateur aurait peut-être encore dû attendre 20 à 30 ans. On lit souvent qu'Internet est né comme réseau de défense américain. En réalité, contrairement à cette « légende tenace et sulfureuse » [Huitema, p. 51], Internet n'a pas été conçu comme réseau de communication militaire ni comme réseau de commande d'engins ou autre application offensive ou défensive. Il naît, certes, de recherches commandités par la DARPA (Defense Advanced Research Projects Agency, Agence des Projets de Recherche Avancés du ministère (américain) de la défense). La DARPA, alors ARPA, a été constituée en 1958 comme une réponse au lancement de Spoutnik, en plein contexte de guerre froide [NASA] : il s'agissait de soutenir des projets technologiques de pointe pouvant induire des développements militaires ou ayant, de manière générale, une portée stratégique. Il ne s'agit toutefois pas directement de recherche militaire. De plus ARPANet est un parmi de nombreux autres projets financés par la recherche publique ou privée aux États-unis et dans d'autres pays.
Internet est-il indestructible ? Cette idée est un des nombreux avatars du « dieu des victoires ». La légende est la suivante : si une bombe atomique touchait un nœud du réseau, les données perdues dans l'explosion seraient retransmises et les suivantes transmises par d'autres voies. Il est possible qu'effectivement les concepteurs d'ARPANet aient eu cela à l'esprit - n'oublions pas le contexte de la Guerre froide - et il est vrai que la commutation de paquets permet de contourner la défaillance de certains nœuds, pour une raison ou une autre. Il reste, toutefois, que cette image très romantique est loin de la réalité d'Internet. Dans la réalité le risque principal n'est pas celui d'une bombe atomique - les risques sont plutôt légaux, commerciaux et surtout logiciels. De ce point de vue, il faut reconnaître que la conception très décentralisée d'Internet le rend effectivement très difficile à contrôler.
La « matrice »[28], nom de ce réseau des réseaux donné par le premier livre d'histoire à son sujet, s'appuie, en revanche sur un fonds culturel et idéologique beaucoup plus bienveillant. Les réseaux et les liens entre ressources sont anticipés dès 1945 par Vannevar Bush dans un article sur un hypothétique memory expander, « Memex ». La première vision d'un réseau de télécommunication, c'est à dire d'interactions sociales, est une série de notes par Joseph Licklider dès 1962 sur un « réseau galactique » [ISOC]. Il anticipe déjà des bibliothèques du futur diffusant le savoir à l'aide d'ordinateurs en réseau. De fait, l'utopie universitaire imprimera sa marque sur les premières conceptions d'Internet [Flichy, p. 55-56]. Les premiers concepteurs de celui-ci sont principalement des jeunes diplômés et étudiants, qui s'organisent « de façon coopérative et égalitaire ». Les comptes-rendus de réunion s'appellent des RFC (« request for comment »), dispositif ouvert. Ce milieu est celui de la science, où la compétence l'emporte largement sur la hiérarchie, « l'échange et la discussion, au détriment des propositions autoritaires » [RFC 3]. Le climat est anti-autoritaire et anti-conformiste : c'est celui des universités de la côte Ouest à la fin des années 1960. « On créa ainsi une communauté de chercheurs en réseau qui croyait profondément que la collaboration a plus d'efficacité que la compétition entre les chercheurs » [RFC 1251].
Autre idéologie forte, plutôt présente dans le monde politique : les autoroutes de l'information. Au départ, le projet, essentiellement politique et industriel, n'a rien à voir avec Internet ; il vise à créer aux États-unis des réseaux de diffusion de programmes d'entertainment (télévision, principalement). C'est d'ailleurs, assez largement un échec, notamment parce que les grands acteurs promeuvent chacun leur système et n'arrivent pas, finalement à se mettre d'accord. On oubliera assez vite cet échec, et c'est Internet qui sera ensuite présenté comme étant le réseau des autoroutes de l'information [Flichy].
L'histoire commence par l'invention de la commutation de paquets qui mènera à de nombreux réseaux. Elle se poursuit par l'intégration de ces réseaux en un unique réseau mondial, Internet. Les services pourront ensuite se développer de façon fulgurante.
Le principe technique du protocole Internet (IP : Internet protocol) est de router les paquets (cf. le cours sur les réseaux). Cette approche des communications informatiques, la commutation de paquets, est élaborée et défendue en 1961 par Leonard Kleinrock (1934-) [ISOC, s. 2]. Il publie le premier livre sur la question en 1964. À partir de là l'idée se répand largement et donnera lieu à de nombreuses recherches puis mises en œuvre, pendant environ deux décennies. Parmi celles-ci citons la première expérience, conduite en 1965 [ISOC], ARPANet, l'ancêtre officiel d'Internet, Cyclades, en France[29], Usenet, basé sur le protocole UUCP intégré à Unix, et Bitnet, qui reliait les gros serveurs académiques au niveau mondial [ISOC]. À la même époque le Xerox PARC développe Ethernet [ISOC, s. 3].
En 1957 Spoutnik est le premier satellite artificiel de la Terre. En 1958, les États-unis constituent l'ARPA pour rattrapper leur retard technologique apparent et prendre une avance décisive, enracinant définitivement l'idéologie du « dieu des victoires. » En 1962 Licklider, le père du « réseau galactique » est le premier directeur du département informatique de l'ARPA [ISOC]. Il sait convaincre son successeur et Larry Roberts (1937-) qui, en 1966, prend la tête de l'équipe qui conçoit ARPANet (publié en 1967), au départ conçu comme un système de messagerie résistant aux défaillances. En septembre 1969 est établi le premier lien. Fin 1969, ARPANet relie quatre ordinateurs : à l'Université de Californie à Los Angeles (UCLA), à BBN (société qui travaille sur les protocoles), à l'Université de Californie à Santa Barbara et à l'Université de l'Utah [ISOC]. ARPANet est destiné à relier des centres de recherche scientifique. Il s'agit donc d'abord d'un outil de recherche scientifique (et technologique), ce qu'il restera encore de façon dominante pendant un quart de siècle.
Comme d'autres réseaux similaires se développaient au cours des années 1970, il devint nécessaire de penser leur interconnexion.
La quasi-totalité des réseaux qui se développent durant les années 1970 et 1980, y compris ARPANet (mais à l'exception de Bitnet et Usenet), sont développés par et pour certaines communautés scientifiques. Il n'y avait donc guère de raisons qu'ils fussent compatibles. Ils ne le furent donc pas, même au sein d'un même pays. Par ailleurs, plusieurs éditeurs de logiciels développaient leurs propres protocoles spécifiques [ISOC]. Toutefois, la recherche scientifique est mondiale et, comme pour le courrier papier, la messagerie électronique ne prend tout son sens qu'en étant globalement interconnectée. En effet, l'intérêt d'un réseau humain pour un individu est proportionnel au nombre d'autres individus qui en font déjà partie. C'est ce que Christian Huitema (un des pères de l'Internet français) appelle poétiquement l'effet de famille [Huitema, pp. 34 sq.]. Bien sûr s'ajoute l'intérêt strictement économique de l'effet d'échelle (très important dans ce cas, les coûts fixes étant très élevés). Ces deux effets combinés font que « connectivity is it's own reward » (la connectivité se récompense elle-même) [Huitema, citant A. Rutkowski].
Dès 1973, Vint (Vinton) Cerf (1943-) et Bob (Robert) Kahn (1938-) proposent d'interconnecter ces différents types de réseaux en imposant un protocole, un langage, commun. Ce protocole devra respecter les prérequis suivants, définis par Kahn [ISOC] :
Chaque réseau est autonome et ne doit pas demander de changement pour pouvoir se connecter à Internet.
Les communications respectent un principe de meilleur effort (best effort) : si un paquet n'atteint pas sa destination, il doit être rapidement réémis.
Les réseaux sont connectés par des boîtes noires (que l'on appellera plus tard passerelles ou routeurs) simples, qui ne conservent aucune mémoire des paquets en transit.
Il n'y a pas de contrôle global du niveau opérationnel (il est décentralisé).
Le protocole pourra donc être compris directement par certains nœuds mais sera d'abord destiné aux passerelles entre réseaux. Ainsi Internet (inter-net = inter-réseau ou réseau international, en anglais), est d'abord un réseau de réseaux. On parle aussi de coalition de réseaux ou (de réseau) d'interconnexion de réseaux, ou encore de fédération de réseaux. Les premières versions d'IP, le protocole Internet, sont publiées en 1978 et les premières mises en place datent de 1981 [Huitema]. Aujourd'hui les différents réseaux hétéroclites sont devenus extrêmement homogènes et utilisent le plus souvent les mêmes protocoles sur toute la planète. Les différents réseaux qui composent aujourd'hui Internet sont donc plus des divisions institutionnelles et commerciales que techniques.
Le passage d'ARPANet sur TCP/IP en 1983 permet de le séparer en un réseau destiné aux activités de défense, MILNET, et en un réseau qui deviendra/s'intégrera à Internet[30].
Joseph Licklider (1915-1990) imagine dès 1957 un réseau de « centres de pensée » constitués d'ordinateurs contenant de gigantesques bibliothèques, sur tous les sujets, et des consoles permettant de tout visualiser à distance. Dans La symbiose Homme-machine (1958), il imagine un avenir où le répétitif serait pour la machine, laissant les œuvres de créativité à l'Homme. En 1962, il rédige une série de notes (dont une publiée en avril 1963) où il imagine un réseau « galactique » ou « intergalactique » permettant d'accéder à tous les programmes et à leurs données « de partout ». Cette note fut extrêmement fructueuse, mais, attention à l'anachronisme : en 1962 il n'y a qu'une dizaine de milliers d'ordinateurs environ (valant pour la plupart plusieurs centaines de milliers de dollars). À l'époque, « partout » désigne essentiellement ces ordinateurs là ; mais la voie est tracée.
Il y a déjà des formes de communication électronique au milieu des années 1960, avant la messagerie Internet. Cette dernière apparaît formellement en 1971, comme un service accessoire, qui n'est pas mis en avant par les promoteurs officiels du réseau. Le « @ » apparaît en 1972 pour le courrier Internet (Ray Tomlinson). En 1973, ce courrier n'est encore qu'informel mais il représente déjà les trois quarts du trafic. Il ne se systématisera que vers la fin des années 1980. Les pièces jointes seront d'abord encodés sous forme de suites de lettres avant d'être réellement jointes d'une façon aisée pour l'utilisateur (MIME, 1992).
Le transfert de fichier (FTP) apparaît, lui aussi en 1971, pour la diffusion de logiciels et de documents scientifiques, principalement. Il deviendra rapidement un dispositif de publication. Ces premiers usages diffuseront largement l'idéal de libre dissémination du savoir quand Internet s'ouvrira au grand public, en particulier quand ils seront relayés par le web naissant.
La convergence numérique est déjà en germe dans la première architecture de von Neumann. Comme le dit Nicholas Negroponte, fondateur du Medialab, « un bit est un bit » : tous les documents reposent sur le même principe de codage numérique de l'information sous forme de fichiers qui peuvent être stockés par les mêmes types de mémoires (de masse ou centrales). Programme ou donnée, vidéo ou texte, carte vectorielle ou photo, tout est égal pour l'ordinateur. Ainsi, elles peuvent, potentiellement, être traitées par les mêmes machines, stockées dans les mêmes mémoires, échangées sur les mêmes réseaux. Des données de toutes natures peuvent également se trouver groupées dans un même document et ce, de façon relativement aisée ; c'est le principe du multimédia. Cette coexistence de plusieurs types de codage de l'information à l'intérieur d'un même document était d'emblée inévitable, même s'il fallut le temps d'une génération humaine pour qu'il émerge.
Ce phénomène de convergence ne concerne pas que les documents. Il a également gagné, progressivement tous les matériels. Les premières consoles de jeu, dans les années 1970 et 1980, rapprochent ordinateur et télévision (Pong, le premier jeu video sur console, sort en 1972). Le Minitel et les serveurs télématiques, dans les années 1980, sont un rapprochement de l'ordinateur et du téléphone[31]. Dans les années 1980 et 1990, le disque vidéo, puis le CD et le DVD, qui fournissent les premiers supports numériques grand public au son et à la vidéo sont eux un rapprochement entre l'ordinateur et la musique et le cinéma-télévision. On arrive ainsi progressivement à des dispositifs tels que les ordiphones (smartphones) qui en un seul artéfact regroupent : téléphone, visiophone, texteur SMS, assistant personnel, ordinateur, visionneuse de films, de musiques, de photos et de textes, récepteur de télévision et radio, navigateur web, etc. Cette évolution touche également les infrastructures puisque les réseaux téléphoniques sont aujourd'hui (presque) intégralement fondus dans les réseaux informatiques. Notons à ce propos, que l'on ne dit plus guère « télé-communication », mais simplement « communication » : l'incidence est prégnante sur nos conceptions de l'espace et du temps elles-mêmes.
Cette convergence n'est pas une simple addition de fonctionnalités, elles permettent aussi des créations hybrides qui mêlent d'emblée images et sons, textes et animations, réalité virtuelle et interaction, etc. Elle occasionne ainsi une nouvelle créativité (le film Tin Tay, des studios Pixar, reçoit un Oscar en 1988). Elle nous force également à repenser les cadres de la création, en particulier concernant “le” droit d'auteur, aujourd'hui encore extrêmement disparate selon les types d'œuvres et de supports. Les œuvres numériques sont comme les idées, telles que les présentait Thomas Jefferson en 1813 : reprendre une idée de quelqu'un ne diminue en rien sa connaissance. Les œuvres numériques, comme les idées, se copient à l'infini, sans diminution de qualité. Ceci pose d'ailleurs un autre problème pour le droit de copie et pour le droit d'auteurs, pensés à une époque où la copie, plutôt que la conception, était l'opération productive de référence.
En prenant un peu de recul on peut voir à l'œuvre un phénomène également présent sur d'autres supports : la transformation d'un moyen de communication en moyen de diffusion, de publication, puis en outil de travail, de production. Pensons à la route : la systématisation des relais de postes ouvre la possibilité des journaux. Pensons à la radio et au développement de la radio-télégraphie durant la première moitié du 20e siècle[32] puis de la radio-téléphonie (à partir de l'époque de la 1re Guerre mondiale), puis de la radio-diffusion (à partir des années 1920 (USA : 1920, France : 1921), dont la TV à partir des années 1930). On retrouve ce type d'évolution pour Internet et les TIC. Durant la seconde moitié du 20e s.: développement de l'ordinateur (à partir des années 1940), puis de la correspondance électronique (à partir des années 1960, dont Internet) puis de la réelle communication numérique (à partir des années 1980, dont le web) puis des outils de travail : ENT, bureaux virtuels, etc.
La publication en-ligne, c'est à dire via un réseau numérique n'est pas née avec le web, pas plus que la navigation hypertextuelle.
Paul Otlet, un des fondateurs de la documentation moderne et père de la classification décimale universelle, imagine dès 1934 un répertoire bibliographique universel, une « Encyclopédie universelle et perpétuelle » et des télescope permettant de lire les livres à distance. Vannevar Bush rêve, en 1945, d'un « memory expander » (Memex), préfiguration d'une base de données regroupant toutes les connaissances et accessible de partout. Pour le Memex, une armée de documentalistes construiraient en permanence des liens entre documents. En 1957, Joseph Licklider, le principal promoteur d'ARPAnet, est un lecteur de V. Bush. Il imagine concrètement un réseau de « centres de pensée » constitués d'ordinateurs contenant de gigantesques bibliothèques, sur tous les sujets, ainsi que des consoles permettant de tout visualiser à distance. Dans le domaine littéraire, citons la nouvelle Le jardin aux sentiers qui bifurquent (1941) de J. L. Borgès, qui peut se lire de façon hypertextuelle. Le mot hypertexte n'est forgé qu'en 1963, par Ted Nelson, qui œuvrera pendant des années pour tenter de construire un système d'information hypertextuel mondial, Xanadu [Flichy, p. 77]. Son projet n'aboutira pas en tant que tel, mais conduira au logiciel Hypercard (1987), sur Macintosh, qui aura beaucoup d'influence.
Concernant la publication en ligne, on trouve les bulletin board systems (BBS), à la fin des années 1970 et durant les années 1980 aux USA (notamment) et, en France, le Minitel dans les années 1980. Évoquons aussi, les newsgroups Usenet. Ce dispositif est créé en 1979. À cette date, ARAPAnet ne réunissait qu'un 8e des départements informatiques étatsuniens [Flichy, p. 71-72]. Divers autres réseaux sont donc lancés à cette époque, notamment pour ceux qui ne bénéficient pas d'ARPAnet. Usenet est l'un d'entre eux ; il a une croissance très rapide : en 1982, 400 sites sont reliés, contre 200 seulement pour ARPAnet. En 1982 des passerelles sont établies entre Usenet et Internet. En 1988, il s'ouvre au public non universitaire. Sur Usenet, puis donc Internet, les newsgroups étaient des forums de discussion très similaires, dans leur fonctionnement, aux forums web actuel. La forme des posts était similaire à un courrier électronique (au départ sans réellement de pièces jointes).
Le premier système d'information distribué, à l'échelle d'Internet fut constitué par l'ensemble des serveurs FTP “anonymes”, c'est à dire qui ne demandaient pas d'identification des utilisateurs. Ces serveurs étaient de différents types. Il pouvait s'agit de simples serveurs de laboratoire ou de département, publiant des documents scientifiques ou des logiciels. Cela pouvait être également de grands dépôts de logiciels gratuits (freeware) ou de partagiciels (shareware). Enfin, pour limiter l'emploi de bande passante et la charge sur les serveurs populaires, nombre de ces dépôts étaient répliqués sur des serveurs dits miroirs accessibles au plus près des utilisateurs. Cette organisation n'est pas sans rappeler l'organisation actuelle des sites, des grandes plateformes d'hébergement et des CDN. À ces serveur s'ajouta plus tard un moteur de recherche, Archie (1990). Suivirent le système Gopher (1991) et son annuaire Veronica, qui rencontrèrent immédiatement un immense succès. En 1993, le service connut encore une croissance de 1 000 %. Ce service permettait de faire des liens de serveur à serveur, mais pas encore de document à document. Enfin arrivèrent le web et ses annuaires et moteurs de recherche. Tim Berners-Lee formule une première proposition de système d'information en 1989. En 1990, il diffuse un premier navigateur. En 1991, il publie le HTTP, le HTML et lance le World-wide web project. Le web commence à se répandre en 1993. C'est aussi cette année-là qu'Internet devient grand public, grâce notamment au web, mais aussi à l'ouverture d'Internet au secteur privé (1991). Les publications papier à propos d'Internet explosent en 1993-1994 [Flichy, p. 16, 43, 113, 250] et les opérateurs d'accès à Internet se développent. Le système des URL est publié en 1994 [RFC1738]. Le premier spam (et sa théorisation) date de 1994, œuvre de deux avocats (dont l'un sera rayé du barreau quelques années plus tard pour publicité mensongère) [Flichy, p. 230-231].
[NASA] Sputnik and The Dawn of the Space Age. NASA. 21 fév. 2003. en ligne : http://www.hq.nasa.gov/office/pao/History/sputnik/.
[ISOC] A Brief History of the Internet. version 3.32. Internet Society. 2003. en ligne : http://www.isoc.org/internet/history/brief.shtml. L'histoire d'Internet par quelques uns de ses pères..
[Negroponte] L'homme numérique. R. Laffont. 1995. Les indications de page sont données à partir de la seconde édition anglaise..
[Verroust] Histoire, épistémologie de l'informatique et Révolution technologique. Université de Paris VIII. 2006 (c. 10/4/2008). en ligne : http://hypermedia.univ-paris8.fr/Verroust/cours/TABLEFR.HTM.
[17] En réalité Niklaus Wirth montre en 1995 que ce n'est pas le cas. C'est la fameuse loi de Wirth : « le logiciel ralentit plus vite que le matériel n'accélère. » L'anglais est plus savoureux : « software gets slower faster than hardware gets faster. » En langage courant : les éditeurs ont une tendant naturelle à transformer les logiciels en “obésiciels” (bloatware) sans que l'amélioration régulière des performances des ordinateurs ne parvienne à le compenser.
[18] Elle est brevetée en 1970, mai des dispositifs similaires ont existé antérieurement, depuis les années 1950 au moins.
[19] Les programmes en assembleur, destinés aux humains, sont « compilés » en langage machine pour être ensuite exécutés. Chaque machine ou famille de machines, puis chaque processeur ou famille de processeurs, possède son propre langage assembleur, très proche en réalité du langage machine lui-même pour ce qui concerne sa sémantique.
[20] Cf. le cours de Technologies informatiques et multimédias.
[21] La programmation fonctionnelle, sans écarter complètement la programmation impérative, est construite sur le principe de la définition et de l'application de fonctions. Mathématiquement, elle met en oeuvre le lambda-calcul définit par Church en 1935.
[22] Les programmes sont des ensembles de règles de déductions.
[23] Le premier langage orienté objet est le Simula (1960). Celui qui diffusa largement l'idée est Smalltalk (1980), beaucoup utilisé en Intelligence artificielle. Celui-ci eut une influence considérable.
[24] Source : le Tiobe Programming community index (index de popularité, pas de nombre de lignes de code produites) : Java 19%, C 15%, C++ 11%, PHP 10%, C# 4%, Javascript 4%. En groupant les différentes versions du C (C, C++, C#) : 30%. En tout : 63%, près de deux tiers.
[25] En réalité la définition de la separation of concerns va souvent plus loin que la modularité et inclut tous les procédés permettant de séparer une tâches en sous-tâches indépendantes que l'on peut traiter chacune de façon plus efficace, voire normaliser. C'est la transposition dans le domaine informatique de la division du travail. De même l'information hiding est le principe général qui consiste à cacher toutes les décisions de conception d'une procédure susceptibles de changer à l'avenir. Son aspect principal est l'encapsulation, le fait de cacher tous les mécanismes internes et structures de données d'une procédure, mais le terme information hiding peut également recouvrir d'autres aspects dont le polymorphisme (un même nom correspond à des procédures différentes, selon le type d'objets auxquels on l'applique).
[26] Joseph Licklider (1915-1990) a un intérêt ancien pour les questions d'interaction entre Homme et ordinateur. Psychologue, il fait, en effet, partie de l'équipe qui conçoit la console du SAGE. Il jouera plus tard un rôle important dans la création d'Internet.
[27] Engelbart brevette la souris en 1970, mais on sait que des dispositifs similaires ont existé, depuis au moins les années 1960, au Xerox PARC.
[28] Ce nom est probablement une référence à l'œuvre de Gibson ou à la série Dr Who.
[29] Cyclades en France et de plusieurs autres réseaux similaires en Europe [Huitema, p. 2]. Ne voir l'histoire qu'à travers ARPAnet est une erreur américano-centrée.
[30] Le passage d'ARPANet à Internet se fait le 1er janvier 1983. En 1982, 40% des nœuds étaient liés aux activités de défense. En 1984, la partie militaire se sépare. [Flichy, p. 60, 71-74]
[31] C'est la première implémentation à grande échelle d'un tel rapprochement, mais dès septembre 1940, à l'occasion du congrès annuel de l'AMS la société Bell avait relié des télétypes au calculateur Model 1 (Manhattan) par lignes téléphoniques. La réponse en moins d'une minute fit forte impression.
[32] 1888 : expérience de Hertz, puis très vite développement de la recherche hors des laboratoires scientifiques ; TSF, dès la toute fil du 19e s., en particulier pour les navires (pour lesquels la technologie filaire ne s'applique pas, rappelons-le) ; dès les années 1910 réseau de communication très étendu, à la surface du globe ; quasi-totalité des stations : armée, marine ou postes
Table des matières
À partir de la fin des années 1990, une nouvelle série de changements techniques, de population d'usagers, d'usages et d'objectifs assignés aux outils numériques se met en place. Il s'agit désormais d'outils d'information et de communication destinés à chaque individu. Désormais le numérique touche de très nombreux aspects de la vie privée comme publique, du travail comme des loisirs.
Si l'on reprend les soixantes ans de l'histoire de l'informatique, nous pouvons distinguer quatre grandes périodes. Avant les années 1940, la notion d'information n'est pas encore définie. Chaque type de bien culturel/informationnel est défini spécifiquement, généralement par son support. Avec les premières générations d'ordinateurs, des années 1950 aux années 1970, apparaissent de nouvelles machines capables de traiter toujours plus d'information, toujours plus vite, pour un encombrement et un prix toujours plus faible. À cette époque l'entreprise dominante est IBM, « big blue ». Vient ensuite l'ère de la loi de Moore, de la fin des années 1970 au début des années 2000, qui voit une forme de compétition/émulation entre le hardware et le software. Les périphériques se multiplient. La puissance des processeurs est multipliée par plus de mille. Les logiciels dominent désormais. Cette période fait la fortune de Microsoft, « big green ». Aujourd'hui, les possibilités matérielles plafonnent, la plupart des usages bénéficient d'une bonne offre logicielle, le développement de l'informatique doit donc une troisième fois changer de nature. Nous sommes désormais dans l'ère des usages : la richesse réside dans les contenus, dans leur organisation, dans leur communication. Cette période voit l'avènement d'Internet et du web. L'entreprise dominante est maintenant Google, « big white ».
Depuis les années 1970 et l'invention du microprocesseur, tous les éléments qui constituent, fondamentalement, un ordinateur sont disponibles sur une simple puce, peu encombrante. La technologie ordinateur, de fait, s'est intégré à de très nombreux dispositifs, les plus quotidiens, de façon à en faciliter la manipulation : électroménager (four à micro-onde, télévision, lave-linge, lave-vaisselle…), automobiles (injection électronique, moteur électrique, navigateur…), robots d'industrie, distributeurs divers (guichet d'autoroute, distributeur de boissons…), automates d'interaction (serveurs “vocaux” téléphoniques, caisses de supermarché automatiques…). L'automatique est désormais omniprésente, pour le meilleur et pour le pire, et personne ne conçoit plus de retour en arrière.
Un des éléments majeurs de cette omniprésence est le dispositif mobile personnel (ou familial) : mini-PC, ordiphone ou tablette numérique. Un moment important de cette histoire commence en 2005 avec le projet humanitaire « one laptop per child » d'équipement d'enfants de pays pauvres à l'aide d'ordinateurs portables à bas coût. Technologiquement, il s'agit de petits ordinateurs dont le coût ne doit pas dépasser 100$. L'engouement est fort pour un certain nombre d'amateurs de technologies et le projet ne tarde pas à essaimer dans le monde commercial sous la forme de mini-PC ou netbooks. Ces mini-PC servent essentiellement à la navigation et à la petite bureautique. Souvenons-nous que cette aspiration de la mobilité informatique est ancienne : l'IBM 650 est (symboliquement) doté de roulettes, le PDP-8 (110 kg) s'affichait dans une décapotable… Notons aussi que le PC classique était alors en panne d'évolution, en particulier en termes d'ergonomie. L'arrivée de ces nouveaux dispositifs rencontre donc très rapidement le succès[33], prolongé par le développement des tablettes numériques, dont l'objectif fonctionnel est similaire. Les mêmes techniques permirent ensuite le développement de téléphones intégrant de véritables ordinateurs, les ordiphones ou smartphones. Aujourd'hui, ces dispositifs mobiles ont dépassé, en nombre d'unités vendues, les ordinateurs proprement dits, fixes et portables[34]. La nature même du commerce électronique en a été changé : les consommateurs sont maintenant, pour beaucoup, connectés en permanence ; ils peuvent acheter en ligne, comme précédemment avec les ordinateurs, mais aussi comparer les prix, les détails techniques ou les avis d'utilisateurs à l'occasion d'un achat. Autre évolution : comme téléphones et tablettes sont généralement géolocalisés, un nouveau marché, dit hyperlocal, se développe, notamment par l'émission de publicités géographiquement ciblées, la réalité augmenté…
L'extension, en termes économiques et en termes d'usages, de ces technologies mobiles, produit à sa suite de nouveaux besoins. La souris doit être remplacés par des interfaces dites « naturelles », qui ne nécessitent pas de table. À la demande de puissance, se substitue, dans un premier temps, une demande d'autonomie, pour laquelle l'industrie, en particulier du microprocesseurs, va faire des efforts considérables (et une nouvelle société, ARM, devient rapidement leader, occultant les fondeurs traditionnels). De même, une demande de mobilité se substitue à la demande ancienne de confort d'utilisation. Le leader des systèmes d'exploitation fixes, windows, est alors complètement dépassé : il cède presque complètement le pas à iOS (Apple) et Android (Google)[35]. Le web, de son côté, devra répondre à une fragmentation considérable du marché de consultation (les dispositifs ont des résolutions et des tailles extrêmement diverses) et devra développer un nouveau mode de conception d'interfaces unifiées. Aux connexions Internet filaires se substitueront des interfaces hertziennes (par radio) : WiFi, 3G, 4G, bluetooth, NFC… Enfin, signe des temps, l'exigence de productivité sera très explicitement remplacée par une exigence d'esthétique : ces dispositifs doivent pouvoir être montrés, et même s'afficher.
Gordon Moore avait initialement prévu la fin de sa loi pour les années 2000. Les technologies qui la fondent nous permettront peut-être de faire encore des progrès jusque 2020, mais l'augmentation de puissance des processeurs uniques plafonnent depuis la fin des années 1990. Il n'est pas indéfiniment possible de diminuer le nombre d'atomes par transistor. Il n'est pas non plus possible d'éliminer complètement l'échauffement d'un circuit qui traite de l'information. Enfin, la vitesse de transmission des impulsions électrique limite la fréquence de l'horloge cadençant les processeurs. Plus nous progressons, plus nous nous rapprochons des limites permises par la physique.
Conscients de ces difficultés, les fabricants de processeurs et d'ordinateurs des années 1990 travaillent donc sur une autre voie de développement : l'augmentation du nombre d'unités de traitement de l'information dans un ordinateur donné (ou répartie sur plusieurs ordinateurs). La piste était déjà exploitée dès les années 1960 par les ordinateurs Cray dits « superscalaires ». Dans les années 1990 on développe donc des processeurs à plusieurs files de calcul[36], puis, dans les années 2000 des puces intégrant plusieurs processeurs (appelés « coeurs ») en parallèle. La technique se développe également de faire travailler plusieurs ordinateurs, parfois en grand nombre, pour collaborer, en parallèle, à une même tâche. L'idée d'un grande machine orwellienne centralisée et omnisciente est commune mais peu probable. Elle disparaît au profit d'ensembles d'agents coopérant les uns avec les autres, d'une façon qui suit les idées développées par Minsky dans The Society of Mind (1987) : l'intelligence ne peut se trouver dans un quelconque processeur central mais plutôt dans un comportement collectif de grands groupes de machines spécialisés hautement interconnectées [Negroponte, p. 157-]. Ainsi, la Thinking Machine Corporation, qui fabriquait des ordinateurs massivement parallèles (les « connection machines ») a disparu au bout de 10 ans (création en 1982, faillite en 1994), principalement parce que le parallélisme pouvait être décentralisé, mis en oeuvre par des séries d'ordinateurs personnels produits en masse [Negroponte, p. 229]. Ainsi le film Titanic (1997) a-t-il utilisé des fermes de calculs pour ses effets spéciaux, plutôt que des super-calculateurs graphiques spécialisés. Aujourd'hui, avec l'augmentation de puissance considérable des processeurs graphiques, on peut même transformer un ordinateur du commerce en super-calculateur en lui adjoignant quelques cartes graphiques.
C'est aussi ce type d'organisation qui permet l'informatique nébuleuse : des serveurs collaborent pour assurer un service qu'ils délivrent, via le réseau, à un terminal léger : navigateur embarqué dans un netbook, une tablette ou un téléphone. Pourquoi alors s'encombrer d'ordinateurs fixes dont la grande puissance n'est plus guère utilisée, sauf pour quelques applications très spécifiques ? Autre avantage pour l'utilisateur : pas besoin d'installer ni de maintenir les logiciels associés, avec tous les problèmes de compatibilité associés. Avantage pour l'éditeur : il vend un service, sur la base d'un abonnement, et non un logiciel, sur la base d'une licence ponctuelle : son client est plus captif et le revenu plus stable dans le temps. Pour tous les services qui le permettent, les principaux éditeurs visent donc, aujourd'hui, le système WICH : web, Internet, cloud, HTML 5. Pour l'instant, nombre d'applications mobiles sont encore installées dans le système, mais de nombreux observateurs anticipent un basculement du marché vers des applications web. Une conséquence, parmi d'autres : la guerre, désormais ouverte, entre les navigateurs, chaque navigateur étant associé à un magasin d'applications.
Les services en ligne datent des années 1980, avant le web et même d'avant l'ouverture d'Internet. Il y avait alors fort peu d'utilisateurs. Ces services explosent en 1993, du fait de l'ouverture d'Internet au secteur privé (1991), de l'extension du web et de la publication de nombreux ouvrages sur le sujet. Jusqu'à la fin des années 1990, on reste toutefois sur des usages relativement limités : publication ou communication. Vers le tournant du siècle la notion de contenu, en particulier produit par les utilisateurs, prend une importance (et une volumétrie) considérable.
Au début de l'informatique personnelle, il s'agit surtout pour les utilisateurs de produire des documents, de les présenter. Après une génération humaine, on se rend compte que les éditeurs de logiciels propriétaires ont abusé de leur position en rendant obligatoire de passer par eux pour accéder aux contenus ; ceci entraîna une prise de conscience du besoin d'interopérabilité et un début de conscience de la primauté du contenu sur le logiciel de création ou de lecture. Deuxième évolution majeure : les réseaux de communication et, donc, le besoin d'échanger ou de communiquer les contenus ; ceci entraîna une standardisation des formats de données, pour les usages les plus courants. Enfin, troisième constat : les effets dits de “pourrissement des bits” ; ceci entraîna la création de formats de données plus pérennes et évolutifs. La donnée, et plus précisément le document (donnée structurée et identifiée) devient ainsi une matière première. Le document n'est plus seulement un ouvrage à la forme fixe mais un contenu diversement exploitable.
Wiener (1950) avait déjà l'intuition que la civilisation se réorganiserait autour de l'information, d'où l'importance centrale de la communication et des contenus. Pour lui, la société est entièrement définie par les messages qui circulent en son sein. Sa vision annonçait déjà la société de l'information, avec ses avantages et ses dangers. L'ordinateur amorce un changement de l'organisation économique qui tourne résolument la page du taylorisme (parcellisation et monotonie des tâches) de la Révolution industrielle dans l'organisation de la production. On parle de « Révolution nootique », « Révolution de l'intelligence » de « Révolution Scientifique et Technique », de « Société Post- Industrielle », etc. [Verroust]. En même temps, une crise économique mondiale multiplie les chômeurs, creuse les inégalités entre les nations et dans les nations. De plus en plus, notre société fait faire par les machines, plutôt qu'avec des machines. La part de la recherche et développement, de la conception plus généralement augmente dans la valeur ajoutée. Il en découle évidemment des bouleversements dans la division traditionnelle du travail, dans le découpage des responsabilités, dans la répartition des qualifications et dans la formation initiale et permanente des travailleurs. Une nouvelle alphabétisation, de la technique, émerge, tout aussi incontournable que celle de l'écriture. De nouvelles professions intellectuelles spécialisées apparaissent. Pour certains auteurs les technologies numériques disposent de qualités propres qui font que leur généralisation est inéluctable. Ainsi, N. Negroponte : “But being digital, nevertheless, does give much cause for optimism. Like a force of nature, the digital age cannot be denied or stopped. It has four very powerful qualities that will result in its ultimate triumph: decentralizing, globalizing, harmonizing, and empowering.” [Negroponte, p. 229]. D'autres, tels que D. Engelbart, voient plus loin encore et considèrent que le numérique a pour finalité d'augmenter l'Homme [Flichy, p. 49-50].
Parmi les évolutions technologiques majeures relevant du numérique et mettant le contenu au cœur, citons rapidement :
La possibilités pour des applications de se communiquer des flux de données. De là, dès 1999, la syndication de contenus entre sites. De là, au cours des année 2010, l'extension d'une demande de données ouvertes (open data), publiques, utilisables par de nombreuses applications tierces. De là les technologies permettant de concentrer d'immenses flux de données sur les utilisateurs de tel ou tel service afin d'adapter celui-ci (ou de contrôler ceux-là) : le big data.
Le crowdsourcing : la possibilité pour le public de participer à la création d'un service, d'un contenu, de grande envergure. Pensons à Facebook, Instagram, Wikipedia, etc. C'est aussi un moyen pour certaines entreprises d'externaliser une partie de sa production sur ses utilisateurs.
L'apparition de nouveaux genres de créations. Évoquons la vague importante actuellement des web documentaires (Arte est championne de ce type de contenus). Évoquons également les livres augmentés par du contenu complémentaire complémentaire en ligne, ou des BD enrichies (p.ex. Megalex). Évoquons encore des jeux vidéos narratifs (p.ex. Heavy rain) ou de pure exploration. Évoquons enfin le journalisme de liens.
L'impression 3D. Les imprimantes servirent d'abord à imprimer des feuilles. Puis l'impression numérique a fait suffisamment de progrès pour permettre l'impression à la demande de livres, ce qui a permis la création de très petites séries. Aujourd'hui, c'est l'usinage additif, ou impression 3D, qui se démocratise, permettant la création de petits objets. Les mêmes principes techniques servent également en médecine reconstructrice ou pour construire des bâtiments.
Puisque les contenus sont une nouvelle ressource, un nouveau pétrole, de nombreux acteurs cherchent à les exploiter, à les capitaliser. Ainsi par exemple, Apple, qui est à première vue un constructeur d'objets numériques, a mis au cœur de sa stratégie le magasin iTunes et est très rapidement devenu le premier vendeur mondial de musique.
Le principe le plus courant de capitalisation est celui du cloud : le contenu, quel qu'en soit sa nature, est chez un fournisseur et l'utilisateur n'en a que la jouissance, pas réellement la possession. D'une démarche de produit et d'artéfact, on passe à un commerce d'usage, de service. Ceci est renforcé par les faits que, primo, nombre d'usagers ont en permanence un dispositif d'accès (habitude du BYOD “bring your own device”) et que, secundo, ils veulent pouvoir utiliser n'importe quel dispositif d'accès (habitude de l'ATAWAD “any time, anywhere, any device”). On achète de moins en moins les biens culturels, en particulier, on loue des flux (streaming). Le cloud vaut également pour les logiciels, qui passent en ligne : SaaS, “software as a service”, et même pour les ordinateurs : PaaS, “platform as a service”.
Tous ces éléments induisent, dans la pratique, un nouveau rapport à l'information, à la connaissance. Celle-ci devient externe, dématérialisée[37] et déproprétarisée[38]. Dans un sens inverse, mais convergent, les objets matériels acquièrent de plus en plus une contrepartie numérique en ligne, ou au sein de bases de données, c'est ce qu'on appelle l'Internet des objets. Chaque artéfact, potentiellement, a vocation à intégrer un catalogue universel, bien au delà de ce que pouvaient faire les bibliothèques avec les œuvres imprimés.
Quand et comment se terminera cette nouvelle ère ? Il est probablement trop tôt pour le dire.
Dans l'avenir immédiat, un certain nombre de producteurs de contenu vont probablement adopter le web sémantique, promu depuis le début des années 2000 par Tim Berners-Lee. En décrivant le contenu sémantique de certaines données publiées sur le web sous une forme logique standardisée, il s'agit d'en permettre une “compréhension” moins grossière par les machines, de leur donner ainsi un premier accès à une partie du sens des textes. Il s'agit également de relier toutes ces données entre elles (méthode dite “linked data”) de façon à réellement construire la base de données mondial que beaucoup de ses usagers croient que le web est. Certains moteurs de recherche intégrent d'ores et déjà certaines de ces informations de façon à rendre les réponses plus pertinentes.
Certains observateurs prédisent une autre fin pour cette période, ou la suivante peut-être : celle du remplacement ou de l'augmentation de l'Homme. Le thème n'est pas nouveau : la littérature de science-fiction, dès ses débuts, illustre le remplacement de l'Homme par la machine, relayant ainsi les craintes déjà exprimées au début de la mécanisation au 19e siècle : citons RUR (Karel Čapek, 1921) et, plus près de nous Terminator (James Cameron, 1984), Matrix (frères Wachowski, 1999) ou la série Real humans (Lars Lundström, 2012). A. Turing est le premier à évoquer sérieusement l'intelligence de machines (« Computing machinery and intelligence », 1950). Il invente à cette occasion le test de Turing, sous le nom « jeu de l'imitation », imaginant un test au cours duquel une machine se ferait passer pour un humain. La machine avait dévalorisé l'Homme travailleur de force ; l'intelligence artificielle remplacera-t-elle l'Homme pensant ? Déjà, chez Wiener, on voit apparaître la possibilité que l'Homme soit dépassé par ses créations. Potentiellement, la machine peut le remplacer pour la plupart des tâches qui ne demandent pas trop d'initiative (et encore). Elle le fera donc probablement… au moins dans une certaine mesure. Pour certains auteurs, la machine succédera donc à l'Homme comme celui-ci a succédé « aux singes ». Pour Marvin Minsky, l'Homme devrait en être fier, plutôt que de s'en inquiéter.
Cette première voie, du remplacement de l'Homme par la machine, l'automatisation, déjà bien amorcée dans certains secteurs économiques, n'est pas la seule. Pour d'autres auteurs, la machine doit être utilisée pour augmenter l'Homme. Certains, anticipent que les ordinateurs devraient atteindre une intelligence comparables à celle des humains vers 2045, ce que Raymond Kurzweil appelle « la singularité », nous n'avons donc pas d'autre choix que d'intégrer la technologie, si l'on ne veut pas purement et simplement disparaître (ou être instrumentalisés, comme dans Matrix). Cette voie est appelée transhumanisme. Ici aussi, la science-fiction nous évoque des images, celles des cyborgs en particulier ; il ne faut pas s'y limiter : il n'y a pas que l'intégration physique de la technique dans le corps humain (ce qui se fait déjà pour compenser certains handicaps). Il y a également l'utilisation des savoirs médicaux, psychologiques, sociaux, etc. pour développer nos potentialités. Suivant les idées de Kurtzweil un certain nombre de chercheurs et d'industriels ont fondé une certain nombre de structures dont l'université de la singularité, qui visent expressément cet objectif. Est-il aussi proche qu'ils le pensent ? Il est, bien entendu, trop tôt pour l'affirmer. Quoi qu'il en soit, une société comme Google a choisi de résolument investir dans cette direction.
[Negroponte] L'homme numérique. R. Laffont. 1995. Les indications de page sont données à partir de la seconde édition anglaise..
[Verroust] Histoire, épistémologie de l'informatique et Révolution technologique. Université de Paris VIII. 2006 (c. 10/4/2008). en ligne : http://hypermedia.univ-paris8.fr/Verroust/cours/TABLEFR.HTM.
[33] Selon l’institut GfK, 500 000 Netbooks auraient été achetés en France en 2008, soit 1 ordinateur par minute.
[34] Les ventes mondiales de smartphones ont dépassé celles des ordinateurs au 4e trimestre 2010.
[35] Début 2014, Android a une part de marché mondiale de 80 à 85% et iOS entre 10 et 15% (et environ l'inverse pour le haut de gamme). Les autres systèmes d'exploitation se partagent environ 4% de part de marché [source : ZDnet, IDC].
[36] Les méthodes dites « RISC », mises en œuvre dès 1965, permettent d'intégrer plusieurs files de calcul à un même processeur. Elles ne se répandent qu'au début des années 1990. Ainsi le processeur grand public Pentium (ou 80586 ou i586) est-il la combinaison de deux files de calcul similaire à son prédécesseur le processeur 80486.
[37] Ce qui ne veut pas dire qu'elle n'a pas de contrepartie matérielle quelque part dans le monde, sur un certain nombre de disques durs, mais qu'elle est mobile et peut se déplacer et ce copier facilement d'un endroit à l'autre, sans que ses utilisateur n'en aient toujours conscience.
[38] Là aussi, l'information a bien, le plus souvent, un propriétaire, mais cette information n'est guère pertinente pour la plupart de ses utilisateurs.